6.2Learning a Naive Bayes Classifier
Given a dataset,{Xin,Y__n}, i= 1..D, n= 1..N, we wish to estimate what these probabilities are. To start with the simplest one, what would be a good estimate for the number of the percentage of spam versus ham emails that our imaginary entity uses to generate emails? Well, we can simply count how many spam and ham emails we have in our data. This is given by,

 P(spam) =# spam emails= Pn_I[_Y__n= 1](6.1) total # emailsN
P(spam) =# spam emails= Pn_I[_Y__n= 1](6.1) total # emailsN
Here we mean withI[A=a]a function that is only equal to1if its argument is satisfied, and zero otherwise. Hence, in the equation above it counts the number of instances thatY__n= 1. Since the remainder of the emails must be ham, we also find that
# ham emailsI[Y_total # emails_N

where we have used thatP(ham) +P(spam) = 1since an email is either ham or spam.
Next, we need to estimate how often we expect to see a certain word or phrase in either a spam or a ham email. In our example we could for instance ask ourselves what the probability is that we find the word “viagra”k_times, with_k= 0,_1,>_1, in a spam email. Let’s recode this as_X_viagra= 0meaning that we didn’t observe “viagra”,_X_viagra= 1meaning that we observed it once and_X_viagra= 2meaning that we observed it more than once. The answer is again that we can count how often these events happened inour data and use that as an estimate for the real probabilities according to which_it_generated emails. First for spam we find,
spam emails for which the word_i_was found_j_times
P_spam(_X__i=j) = (6.3) total # of spam emails
(6.3) total # of spam emails
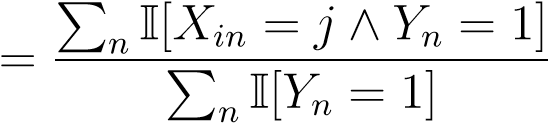 (6.4)
(6.4)
Here we have defined the symbol∧to mean that both statements to the left and right of this symbol should hold true in order for the entire sentence to be true.
For ham emails, we compute exactly the same quantity,
ham emails for which the word_i_was found_j_times
P_ham(_X__i=j) = (6.5) total # of ham emails
(6.5) total # of ham emails
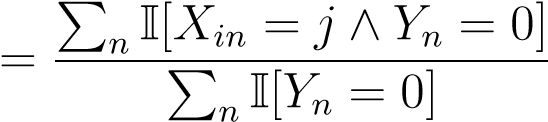 (6.6)
(6.6)
Both these quantities should be computed for all words or phrases (or more generally attributes).
We have now finished the phase where we estimate the model from the data. We will often refer to this phase as “learning” or training a model. The model helps us understand how data was generated in some approximate setting. The next phase is that of prediction or classification of new email.