3 MODELO DE CASEY (2004)
Cualquiera de los modelos anteriores es válido para describir el proceso de un análisis forense de evidencias digitales, unos con mayor detalle que otros. Paralas intenciones de este proyecto me he basado en el modelo de Casey ya que es el menos abstracto y quizás el más extendido. Como podemos apreciar, con el paso de los años los modelos tienden a tener más etapas para describir el proceso de investigación. Elmodelo de Casey ha evolucionado desde el primer modelo presentado en el 2002 hasta el modelo publicado en el 2004 en su segunda edición de su libro [7] que recoge los siguientes pasos:
Autorización y preparación
Identificación
Documentación, Adquisición y Conservación
Extracción de Información y Análisis
Reconstrucción
Publicación de conclusiones
Autorización y Preparación:Lo primero que se debe hacer es ir a la escena del delito a recoger pruebas, pero antes debemos prepararnos con el material y los permisos necesarios para llevarlo a cabo.
Identificación:Una vez que estamos en la escena del delito debemos identificar todo el hardware y software que encontremos.
**Documentación:Esta etapa se realiza durante todo el proceso. Debemos anotar todos los pasos realizados para ayudar a una reconstrucción final de los hechos y con mayor detalle aún si se va a presentar como prueba en un juicio.
Adquisición:Debemos extraer todo el hardware encontrado que pueda tener pruebas. Generalmente la prueba no es el hardware en sí (huellas digitales, números de serie de CPU), sino el contenido de los mismos. De modos que debemos extraer una imagen de cada dispositivo encontrado.
Conservación:El hardware debe conservarse de forma que no se altere su contenido y es primordial hacer varias copias de la imagen extraída de cada dispositivo y nunca manipular el original.
Examen y Análisis:Con todos los datos obtenidos en las etapas anteriores podemos tener una idea de donde empezar a buscar, por lo que debemos elaborar una hipótesis y a partir de ella comenzar a recopilar datos que nos ayuden a confirmarla. Existen multitud de métodos paraextraer datos de un sistema de ficheros que podemos usar para este fin.
Reconstrucción:Una vez que tenemos datos suficientes debemos ser capaces de responder a las preguntas ¿que pasó? ¿quien lo hizo?¿cuando?¿donde? y en ultima instancia ¿porque?
Publ**icación de conclusiones:**Los resultados de los análisis forenses deberían publicarse en la medida de lo posible para incrementar el conocimiento de otros investigadores y en último caso para posibles sistemas expertos que en el futuro puedan ayudar en estecampo.
El proceso puede verse como en la siguiente figura: cada flecha indica el flujo de información, de modo que la información que obtenemos en una etapa nos sirve para la siguiente y viceversa. En cualquier momento se puede usar lo que se sabe en una etapa para volver a la etapa anterior y obtener más datos. Toda la información generada se guardará como documentación que nos servirá para la publicación final.
IDENTIFICACIÓN
DE HARDWARE
AUTORIZACIÓN Y
PREPARACIÓN
IDENTIFICACIÓN
DE SOFTWARE
ADQUISICIÓN DE
HARDWARE
EXAMEN Y
ANÁLISIS
RECONSTRUCCIÓN
ADQUISICIÓN DE
SOFTWARE
PUBLICACIÓN DE
CONCLUSIONES
ADQUISICIÓN DE
SOFTWARE EN VIVO
CONSERVACIÓN
DE SOFWARE
CONSERVACIÓN
DE HARDWARE
CONSERVACIÓN
DE SOFTWARE
32Herramienta de apoyo para el análisis forense de computadoras
3.1 Autorización y Preparación
Autorización
El objetivo detrás de cualquier investigación realizada por un forense o un equipo de respuesta rápida sobre un sistema de ficheros puede ser de tipo 'legal' o 'casual'. Teniendo en consideración que estos términos no tienen un significado estandarizado para describir los motivos de una investigación y cada uno de ellos se diferencia bastante del otro debemos detallar más.
Investigación Legal: La mayoría de las investigaciones forenses de tipo legal tienen como objetivo asistir a los órganos oficiales a llevar acabo una investigación criminal a fin de llevar ante la justicia al culpable del delito. En investigaciones de este tipo es imprescindible seguir de forma estricta los procedimientos para el tratamiento de pruebas que van a ser presentadas en el juzgado. Por ejemplo, el mero error de sobreescribir cualquier prueba en el sistema de ficheros por información aleatoria (pérdida de datos) es suficiente para considerar el resto de las pruebas de la misma índole como inviables por parte de un juez o fiscal.Investigaciones legales, a menudo, únicamente se limitan a la conservación de datos y esfuerzos de mantener la integridad de información en el sistema de ficheros una vez el hecho del compromiso ha sido probado. Las pruebas tras ser tratadas de forma correcta se transfieren al poder de órganos oficiales para ser analizados por parte de sus recursos. El nivel de participación del forense en la investigación una vez las pruebas han sido transferidas depende del deseo del denunciante y la voluntad de órganos oficiales.
Investigación Casual: Cualquier tipo de investigación casual no tiene como objetivo la persecución legal del individuo responsable del acto criminal. La investigación se realiza por el interés desde el punto de vista forense, por lo tanto las técnicas, herramientas y metodología utilizada puede ser usada de forma más agresiva. La realización de una investigación forense casual requiere más conocimiento y experiencia por parte del investigador, ya que en estos casos no existen requerimientos estrictos de terceros referentes a la cantidad y calidad de pruebas obtenidas.
Antes de manipular una evidencia digital, hay muchas cosas que se deben considerar. Una de ellas es que estemos seguros de que nuestra búsqueda no va a violar ninguna ley o dar lugar a responsabilidades legales.
Los profesionales de la seguridad en computadores deberían obtener instrucciones y autorizaciones escritas de sus abogados antes de realizar cualquier investigación dentro de una organización. Una política de organización determina en gran parte si se pueden buscar en las computadoras de los empleados, analizar los e-mails y otros datos. Sin embargo, una búsqueda justificada normalmente se necesita para acceder a las áreas que un empleado consideraría personales o privadas sin su consentimiento. Hay algunas circunstancias que permiten búsquedas justificadas en un lugar de trabajo, pero los profesionales de la seguridad deben dejar estas decisiones a sus abogados.
Preparación
Antes de empezar un análisis forense se recomienda describir como se va a realizar la recolección de evidencias. Si es posible tener acceso a alguien que esté íntimamente relacionado con la computadora, obtener información general como el tipo de computadora, su sistema operativo, si esta en una redLAN, en Internet, etc. Además puede que necesitemos algunas herramientas como CD’s Forenses, contenedores adecuados para transportar el hardware, y otras herramientas como puede ser un destornillador.
3.2 Documentación
La documentación es esencial en todas las fases del manejo y procesamiento de evidencia digital. Documentando quien adquiere y maneja evidencias en un momento dado es algo imprescindible para mantener laCadena de Custodia. Esto no es algo inusual para alguien que maneja una evidencia para posteriormente presentar las conclusiones ante un juicio.
La continuidad de la posesión o Cadena de Custodia debe ser establecida para que la evidencia sea admitida como válida, aunque frecuentemente todas las personas involucradas en la adquisición, transporte y almacenamiento de evidencias son llamados para testificar en un juicio. De modo que, para evitar confusiones y mantener el control completo de la evidencia en cada momento, la Cadena de Custodia debería estar obligada a cumplir un mínimo.
Así que, debería anotarse cuidadosamente cuando se adquiere la evidencia, de donde y por quien. Por ejemplo, si la evidencia se copia en un disquete, deberíamos anotar en la etiqueta del mismo y en la cadena de custodia la fecha y hora actuales, las iniciales de la persona que hizo la copia, como hizo la copia y la información relativa al contenido del disquete. Adicionalmente,los valores MD5 o SHA de los archivos originales deberían ser notados antes de copiarse.
A continuación podemos ver un ejemplo deuna Cadena de Custodia con información mínima para un disco duro cuyo número de serie es el 123456.

Si la prueba es pobremente documentada,entonces un abogado puede arrojar dudas más fácilmente sobre las habilidades de los interesados y puede convencer al tribunal de no aceptar la evidencia.
La documentación que muestra que la evidencia se encuentra en su estado original se usa regularmente para demostrar que es auténtica y que está inalterada.
Documentar la posición original de prueba también puede ser útil al tratar de reconstruir un delito. Cuando existen varias computadoras implicadas, asignando letras a cada posición y números para cada fuente de prueba digital ayudarán a seguir la pista a los ítems. Además, los investigadores digitales pueden estar obligados a brindar testimonio años más tarde o, en el caso de muerte o enfermedad, un investigador digital puede ser incapaz brindando testimonio. Entonces, la documentación debería proveer todo lo que alguien más necesitará muchos años más tardepara entender la evidencia. Finalmente, al examinar prueba, se requieren notas detalladas para posibilitar a otro investigador competente a evaluar o reproducir lo que estaba hecho e interpretar los datos.
3.3 Identificación
La identificación de las evidencias digitales es un proceso con dos pasos:
Primero, el investigador debe reconocer el hardware (por ejemplo, ordenadores, disquetes o cables de red) que contienen información digital.
Segundo, el investigador debe distinguir entre la información relevante y otros datos intrascendentes según lo que estemos buscando.
3.3.1 Identificación de Hardware
Hay muchos productos computerizados que pueden tener evidencias recogidos en [3], como telefonos, dispositivos inalámbricos, PDAs, Routers, Firewalls y otros dispositivos de red. Hay muchas formas de almacenar datos multimedia, como disquetes, cds, cintasmagnéticas, pen drives, memory cards, etc.

Una selección de hardware.
Vamos a ver a continuación los diferentes componentes que podemos encontrarnos en una escena del delito y las evidencias que se pueden extraer de ellos:
Dentro de un PC:
Unidad Central de Procesamiento(UCP o CPU)
Descripción:A menudo llamadas el “chip”, es un microprocesador alojado dentro de la torre de la computadora, en un circuito electrónico junto con otros componentes. Esta puede ser o no extraíble.





Usos principales:Realiza todas las funciones aritméticas y lógicas en la computadora. Controla el funcionamiento de la computadora.
Evidencia Potencial:El dispositivo en sí mismo pueden ser una prueba de robo, falsificación, o remarcado de numero de serie.
Memoria
Descripción:Circuito electrónico extraíble situado en el interior de la computadora. La información que se almacena aquí normalmente no se mantiene cuando se apaga la computadora.




Usos principales:Almacena los datos y programas del usuario cuanto la computadora está en ejecución.
Evidencia Potencial:Igual que el anterior.
Discos duros
Descripción:Una caja precintada que contiene discos recubiertos con una sustancia capaz de almacenar datos magnéticamente. Puede encontrarse internamente dentro de un PC o como un disco externo. Su contenido puede estar sin formatear o formateado, de forma que estaríaorganizado en un sistema de ficheros.



Usos primarios:Almacenamiento de información como programas, texto, imágenes, video, multimedia, etc.
Evidencia Potencial:Todas las que se puedan encontrar en un sistema de ficheros (véase el apartado de identificación de software)
Dispositivos de Control de Acceso
Descripción:
- Una tarjeta inteligente (smart card), o tarjeta con circuito integrado (TCI), es cualquier tarjeta del tamaño de un bolsillo con circuitos integrados incluidos. Aunque existe un diverso rango de aplicaciones, hay dos categorías principales de TCI. Las Tarjetas de memoria contienen sólo componentes de memoria no volátil y posiblemente alguna lógica de seguridad. Las Tarjetas microprocesadoras contienen memoria y microprocesadores.
La percepción estándar de una "tarjeta inteligente" es una tarjeta microprocesadora de las dimensiones de una tarjeta de crédito (o más pequeña, como por ejemplo, tarjetas SIM o GSM) con varias propiedades especiales (ej. un procesador criptográfico seguro, sistema de archivos seguro, características legibles por humanos) y es capaz de poveer servicios de seguridad (ej. confidencialidad de la información en la memoria).


- Un “dongle” es un pequeño dispositivo que se conecta a un puerto (puerto paralelo, USB, etc) del ordenador, y gracias a él se verifica que un programa es original y no una copia. Cuando no está conectado al PC, el software funciona en modo restringido o simplemente no funciona.


- Un escáner biométrico es un dispositivo conectado a un sistema computacional que reconoce características físicas de un individuo (por ej., huellas digitales, la voz o la retina).

Usos principales: Permite el acceso al control de computadoras, programas o a funciones, funcionando como una clave de encriptación.
Evidencia potencial: Información de identificación/autenticación de los usuarios, nivel de acceso, configuraciones, permisos y el dispositivo en sí mismo.
Contestadores automáticos
Descripción:Un dispositivo electrónico que es parte de un teléfono o está conectado entre un teléfono y la conexión a la red. Algunos modelos usan una cinta magnética, mientras que otros usan un sistema de grabación electrónico (digital).

Usos pri**ncipales:**Almacena mensajes de voz de la persona que llama cuando la parte llamada no contesta a la llamada. Normalmente muestra un mensaje de voz de la parte llamada antes de grabar el mensaje.
Evidencia Potencial:Los contestadores automáticos pueden almacenar mensajes de voz y, en algunos casos, información sobre fechas y horas sobre cuando se dejó el mensaje. También pueden contener otras cosas almacenadas:
-Información de identificación de la persona que llama.
-Mensajes borrados. --El último número llamado --Notas recordatorias.
-Nombres y números de teléfono.
-Cintas.

Cámaras Digitales
Descripción:Dispositivo de grabación digital para imágnees y video, con un dispositivo de almacenamiento en su interior y hardware de conversión que permite transferir los datos a la computadora.

Usos principales:Captura imágenes y/o video en un formato digital que es fácilmente transferible a una computadoras para visualizar o editar.
Evidencia Potencial
- Imagenes.
- Sellos de fecha y hora.
- Carretes/Tarjetas de memoria.
- Video.
- Sonido.
Dispositivos Portátiles (Asistentes Digitales Personales) [PDAs], Agendas Electrónicos)
Descripción:Un asistente digital personal (PDA)es un computador de mano originalmente diseñado como agenda electrónica. Hoy en día se puede usar como una computadora doméstica (ver películas, crear documentos, navegar por Internet...).

Usos Primarios:Computación de mano, almacenamiento y comunicación.
Evidencia Potencial
14
- Libreta de direcciones.-- Información sobre citas
-Documentos.
-E-mails.
- Escritura a mano.
-Passwords.
- Libreta de teléfonos.
-Mensajes de texto.
-Mensajes de voz.
Tarjetas de Memoria
Descripción:Dispositivos electrónicos de almacenamiento extraíbles, que no pierden la información cuando no se suministra con corriente de la tarjeta. Estas tarjetas suelen tener una memoria de tipo flash, aunque en algunos casos, como en las compactFlash, se le puede incluir un minidisco duro, que aunque almacena más información, es más sensible a los golpes y consumemás energía. Se usan en una variedad de dispositivos como cámaras digitales, MP3s, PDAs, ordenadores, etc.

Algunos ejemplos son:
- CompactFlash (CF) I y II

- Memory Stick (MS)


- MicroSD

- MiniSD

- Multi Media Card (MMC)

- Secure Digital (SD)

- SmartMedia Card (SM/SMC)

- xD-Picture Card

Usos principales:Proporciona métodos adicionales extraíbles para el almacenamiento y transpote de información.
Evidencia Potencial:Todas las que se puedan encontrar en un sistema de ficheros (véase el apartado de identificación de software)
Componentes de redes de ordenadores
Módems
Descripción:Módems, internos y externos (analógicos, DSL, ISDN, cable), inalámbricos, etc.





Usos principales:Un módem se usa para facilitar la comunicación electrónica, permitiendo a la computadora acceder a otras computadoras y/o redes via línea telefónica, inalámbrica u otro medio de comunicación.
Evidencia Potencial:El módemen sí mismo.
Tarjetas de Red de Área Local (LAN) o Tarjetas de Interfaz de Red (NIC)
Descripción:Tarjetas de red y cables asociados. Estas tarjetas también pueden ser inalámbricas.
Usos principales:Una tarjeta LAN/NIC se usa para conectar computadoras. Las tarjetas permiten el intercambio de información y de recursos.
Evidencia Potencial:El dispositivo en si mismo, dirección MAC(Media Access Control).
Routers, Hubs, y Switches
Descripción:Estos dispositivos electrónicos se usan en sistemas de redes de computadoras. Los routers, switches y hubs proporcionan un medio para conectar diferentes sistemas de computadoras o redes.



Usos principales:Equipamiento usado para distribuir y facilitar la distribución de datos a través de redes de computadoras.
Evidencia Potencial:Los dispositivos en sí mismos. Además, para los routers, sus ficheros de configuración.**
Servidores
Descripción:Un servidor es una computadora que proporciona algunos servicios a otras computadoras conectadas a él vía red. Cualquier computadora, incluyendo un ordenador portátil puede configurarse para ser un servidor.



Usos primarios:Proporciona recursos compartidos como e-mail, almacenamiento de ficheros, servicios Web y servicios de impresión para una red de ordenadores.
Evidencia Potencial:Todas las que se puedan encontrar en un sistema de ficheros (véase el apartado de identificación de software)
Cables y conectores de Red
Descripción:Los cables de red pueden tener diferentes colores, grosores y formas, dependiendo de los componentes a los que esté conectado.

Usos principales:Conecta componentes de una red de computadoras.
Potential Evidence:La evidencia son ellos mismos.
Dispositivos Buscapersonas (Buscas)
Descripción:Un dispositivo electrónico de mano, que puede contener evidencias volátiles (números de teléfono, correo de voz, e-mail, etc.). Los PDAs y los móviles también pueden usarse como dispositivos buscapersonas.




Usos principales:Para enviar y recibir mensajes electrónicos, numéricos (números de teléfono, etc.), y alfanuméricos (texto, a menudo incluyendo e-mail)
Evidencia Potencial:
- Información de direcciones
- Mensajes de texto -- E-mail.
- Mensajes de voz
- Números de teléfono
Impresoras
Descripción:Un sistema de impresión térmico, de láser, de tinta o de impacto, conectado a la computadora via cable (serie, paralelo, USB, firewire, etc.) o por puerto infrarrojos. Algunas impresoras contienen un buffer de memoria, permitiéndoles recibir y almacenar múltiples páginas de documentos mientras imprimen. Algunos modelos incluyen un disco duro.




Usos principales:Imprimir texto, imágenes, etc., de la computadora al papel.
Evidencia Potencial:Las impresoras pueden mantener logs de su uso, información de fechas y horas, y además, si esta conectada a una computadora, puede almacenar información de su identidad de red.
8
-Documentos.
-Disco duro.
-Cartuchos de tinta.
-Información/identidad de red.
-Imágenes sobreimpresas en el rodillo
-Sellos de fecha y hora
-Log del uso del usuario
Dispositivos Removibles de Almacenamiento y Multimedia
Descripción:Soporte usado para almacenar información eléctrica, magnética o digital. (por ej., disquetes, CDs, DVDs, cartucho, cinta).






Usos principales:Dispositivos portátiles que pueden almacenar programas, texto, fotos, video, archivos multimedia, etc.
Evidencia Potencial:Todas las que se puedan encontrar en un sistema de ficheros (véase el apartado de identificación de software).
Escáners
Descripción:Un periféricoque se utiliza para convertir, mediante el uso de la luz, imágenes impresas a formato digital.
Hay varios tipos. Hoy en día los más extendidos son los planos.
Tipos:
- _De rodillo:_Como el escáner de un fax

- _Planos:_Como el de las fotocopiadoras.

- _De mano:_En su momento muy económicos, pero de muy baja calidad.
Prácticamente extintos.

Hoy en día es común incluir en el mismo aparato la impresora y el escáner. Son las llamadas impresoras multifunción.

Usos principales:Convierte documentos, imágnees a ficheros electrónicos que pueden verse, manipularse o transmitirse en una computadora.
Evidencia Potencial:El dispositivo en sí mismo puede ser una evidencia. La posibilidad de poder escanear podría ser una ayuda para actividades ilegales (pornografía infantil, fraude de cheques, falsificación y robo de identidad). Además, existen imperfecciones como las marcas en el cristal que pueden permitir realizar una identificación única de un escaner usado para procesar ciertos documentos.
Teléfonos
Descripción:Undispositivo de telecomunicación diseñado para transmitir conversación por medio de señales eléctricas. Puede ser individual (teléfono móvil) o dependiente de una estación base remota (inalámbricos), o conectados directamente a la toma de teléfono (fijo).






Usos principales:Comunicación bidireccional desde un dispositivo a otro usando lineas terrestres, transmisión de radio, sistemas celulares o una combinación. Los teléfonos son capaces de almacenar información.
Evidencia Potencial:Muchos teléfonos pueden almacenar nombres, números de teléfono, e información de identificación de las personas que llaman. Además, algunos teléfonos celulares pueden almacenar informaciones sobre citas, e-mail y registros de voz.
-Calendario/información sobre citas.
-Passwords.
-Información sobre personas de contacto
- Libreta telefónica
-Número de serie electrónico
-Mensajes de texto --E-mails.
-Mensajes de voz.
-Notas recordatorias
-Navegadores web
Instrumentos electrónicos varios
Hay muchos tipos adicionales de equipamiento electrónico que son muy numerosos para ser listados y que podrían encontrarse en una escena del delito. Sin embargo, hay muchos dispositivos no tradicionales que pueden ser una excelente fuente de información investigativa y/o evidencia. Ejemplos de estos son: equipamiento de clonación de móviles, faxes, fotocopiadoras, grabadoras de audio, grabadores de bandas magnéticas de tarjetas de crédito, etc.
Fotocopiadoras



Algunas fotocopiadoras mantienen registros de acceso de usuario e históricos de las copias hechas.
Evidencia Potencial:
-Documentos.
-Logs de acceso de usuarios.
-Sellos de fecha y hora.
Copiadores de bandas magnéticas


Los Credit card skimmers se usan para leer la información de la banda magnética de tarjetas de plástico.
Evidencia Potencial:La información contenida en la banda magnética incluye:
-Fecha de caducidad de la tarjeta --Dirección del usuario.
-Número de tarjeta de crédito
-Nombre de usuario.
Máquinas de FAX

Los faxes pueden almacenar números de teléfono programados y un histórico de documentos transmitidos y recibidos. Además, algunos contienen memoria que permite faxes multipágina. Algunos pueden contener cientos de páginas de faxes entrantes y/o salientes.
Evidencia Potential:
-Documentos.
-Números de teléfono.
-Carrete.
-Logs de faxes enviados/recibidos
Global Positioning Systems (GPS)



Los GPSs pueden proporcionar información sobre viajes previos mediante información del destino, puntos intermedios y rutas. Algunos almacenan automáticamente los destinos previos e incluyen logs de viajes.
Evidencia Potencial:
-Dirección de la casa
-Coordenadas de puntos intermedios.
-Destinos previos.
-Nombres de lugares.
-Logs de viajes
3.3.2 Identificación del software
Generalmente se considera que todo el contenido del hardware identificado contiene potencialmete evidencia digital. Por esto, una vez que se ha retirado el hardware para su análisis en el laboratorio, se debe extraer su contenido. Por esto no podemos identificar las evidencias digitales hasta que no hayamos adquirido el hardware y extraído el software que contiene. Pero existen algunos casos en los que se pueden identificar evidencias digitales en el lugar del delito. Es lo que llamamos una adquisición de datos en vivo, que se realiza cuando el sistema se encuentra encendido o no se puede apagar por diversas razones, como que se trate de un sistema crítico (sistemas informáticos de los hospitales).
En este punto debemos decir que hay dos tipos de datos:
Datos volátiles: son datos que se pierden si el sistema es apagado. Ejemplos de los mismos puede ser una lista de procesos en ejecución y usuarios activos.
Datos No Volátiles: son datos que no se pierden cuando apaga el sistema e incluyen el disco duro.
Por tanto sabemos quesi apagamos un sistema encendido perderemos los datos volátilesy en algunos casos puede ser muy interesante obtenerlos. Para determinar que evidencia recoger primero debemos seguir elOrden de Volatilidad: una lista de fuentes de evidencias ordenadas por su volatilidad relativa.
En general puede verse de la siguiente manera:
| Registros, memoria de periféricos, cachés, etc. | nanosegundos |
|---|---|
| Memoria Principal | Nanosegundos |
| Estado de la Red | Milisegundos |
| Procesos en ejecución | segundos |
| Disco | minutos |
| Disquetes, copias de seguridad, Discos duros, etc. | Años |
| CD-ROMs, DVDs, etc. | Decenas de años |
Un ejemplo de orden de volatilidad podría ser:
Registros y cache
Tablas de enrutamiento
Cache Arp
Tabla de procesos en ejecución
Estadísticas y módulos Kernel
Memoria principal
Ficheros temporales del sistema
Memoria secundaria
Configuración del Router
Topología de red
Una vez que hemos obtenido la información volátil debemos pensar en apagar el sistema. Una de las decisiones más difíciles al encontrarse con una computadora sospechosa que esta encendida es cómo apagar el sistema de manera que no se corrompa la integridadde los archivos. En la mayoría de los casos, el tipo de sistema operativo empleado en la computadora será la clave a la hora de tomar esta decisión. Con unos, bastará con tirar del enchufe del ordenador, y en otros, desconectando el PC sin permitir al sistema operativo iniciar sus comando internos de apagado podría resultar desde la pérdida de archivos vitales hasta la rotura del disco duro.
El problema es que si usamos cualquier comando o funcionalidad del sistema para apagar el sistema, corremos el riesgo de que se ejecute código malicioso o de que se modifiquen los logs del sistema. Por ejemplo, los comandos “shutdown” o “sync” podrían haber sido modificados de forma que cuando los ejecutemos el sistema borre ficheros críticos. Por lo tanto es preferible usar nuestros propios ejecutables de forma externa.
El riesgo típico de tirar del cable de la pared es que el sistema estará en un estado inconsistente, y cuando el sistema se encienda de nuevo iniciará un proceso intensivo de reconstrucción.
Generalmente parece que hay una regla aceptada que dice“si esta encendido, no lo apagues, y si esta apagado, no lo enciendas”. En caso de que esté encendido lo más común es simplemente fotografiar la pantalla y tirar del cable de la pared. Deberemos anotarque se tiró del cable para tener en cuenta más tarde que el SSOO puede estar en un estado inconsistente. Esto es útil saberlo sobre todo si más tarde se decide arrancar el sistema de nuevo en un entorno seguro.
En el caso de que no se pueda apagar el sistema por ser crítico su funcionamiento, se debe hacer un análisis mínimamente intrusivo intentando recopilar la mayor cantidad de datos posibles relacionados con la investigación. Esto puede verse con mayor detalle en la sección de “Examen y Análisis”, donde se pueden ver los archivos que son interesantes según el tipo de delito.
3.4 Adquisición
Una vez identificadas, las evidencias deben ser recogidas y conservadas de modo que puedan ser identificadas después con facilidad. Una buena forma de hacer esta recogida es de forma que no se alteren. Imagínese por un momento una supuesta escena del crimen donde haya una nota suicida escrita en la pantalla. Antes de examinar el contenido digital de la computadora se debería antes fotografiar la pantalla y tomar huellas digitales.
Pero aquí nos topamos con otro problema: ¿que hacemos cuando nos encontramos una computadora encendida? ¿La apagamos directamente? Si manipulamos la computadora en busca de datos podemos alterar la evidencia. Por ejemplo, si encontramos una computadora conun sistema Linux y probamos a hacer un ‘ls’ para ver el listado actual de un directorio, modificaremos los registros de actividad, el contenido de la memoria ram, etc.
3.4.1 Adquisición del hardware
Aunque este apartado se base en los datos almacenados en las computadoras, vamos a hacer una mención al hardware para asegurarnos de que la evidencia que contiene se conserva correctamente.
Hay dos factores que se deben considerar al recolectar el hardware. En un lado, para no dejar ninguna evidencia atrás, un investigador puede decidir que hay que recoger todas las piezas que se encuentren. Por otro lado, un investigador puede recoger solo lo esencial para ahorran tiempo, esfuerzo y recursos. Algunas computadoras de instituciones en continuo funcionamiento, como hospitales, el hecho de modificar algo puede costar vidas humanas. En algunos casos, simplemente no es factible recoger el hardware por su tamaño o cantidad.
¿Que hacer si una computadora esta conectada a otra? En una era en la que las redes de computadoras son lo habitual, sería absurdo pensar que podemos obtener todas las computadoras que están conectadas a una dada. En una red de área local situada en un piso, edificio o en un campus universitario, un PC puede estar conectado a cientos de computadoras. Este PC puede además estar conectado a internet, por lo que deberíamos tomar muchas computadoras en todo el mundo. En definitiva, esta elección se debe tomar en función del número de pruebas que necesitemos y los recursos para almacenarlas que dispongamos.
Si se decide recoger una computadora entera, deberían considerarse todos sus periféricos, como impresoras o unidades de cinta. Las hojas impresas que estén relacionadas con la computadora pueden contener información que ha sido cambiada o borrada de la computadora, como números de teléfono, direcciones de e-mail, etc. Además se recomienda mirar en la basura en busca de evidencias. Un conocido investigador forense una vez bromeó acerca de que cuando él llegaba a su casa y su familia estaba ya durmiendo en la cama, no despertaba a su esposa para preguntarle lo que había hecho durante el día, sino que simplemente examinaba la basura.
3.4.2 Adquisición del software
Cuando se trata con evidencias digitales, lo principal es el contenido de la computadora más que el hardware en sí. En este apartado veremos como se adquieren estos contenidos de forma que no se altere la información que contienen y podamos estar seguros de que tenemos una copia exacta.
Hay dos tipos de adquisición de datos: en vivo o post-mortem. La diferencia está basada en el sistema operativo usado durante la copia:
Una adquisiciónen vivoocurre cuando los datos son copiados desde un sistema sospechoso usando el sistema operativo sospechoso. Esta se hace normalmente antes de la adquisición de hardware y fue mencionada previamente en el apartado de Identificación de Software.
Una adquisiciónpost-mortemse realiza cuando el dispositivo a analizarno está en ejecución y por tanto los datos son copiados posteriormente en un entorno controlado. Esto ocurre cuando el disco es extraído del sistema sospechoso y ubicado en un sistema controlado, y también cuando el sistema sospechoso es arrancado con undispositivo autoarrancable, por ejemplo, un CD-Rom.
En general son preferibles las adquisiciones post-mortem sobre las adquisiciones en vivo, ya que no hay peligro de que el sistema operativo nos de información falsa. Algunos casos requieren una adquisición en vivo, por ejemplo:
Cuando el sistema es un servidor crítico que no puede apagarse por los daños que ocasionaría.
Cuando los datos necesitan ser adquiridos pero un apagado podría alertar a un atacante de que el sistema ha sido identificado (en el caso de Hackers).
Cuando los datos se perderán cuando se desconecte de la electricidad. Ejemplos incluyen la memoria y volúmenes encriptados que son montados y la clave es desconocida.
Hay dos opciones cuando se recoge una evidencia digital de una computadora: copiar solamente la información que se necesita o copiarlo todo. Si se va a hacer un examen rápido o si solo una pequeña parte de la evidencia es de interés (por ejemplo, un fichero log), es más práctico buscar inmediatamente en la computadora yobtener la información requerida. Sin embargo, si hay abundancia de evidencias en la computadora, es recomendable copiar el contenido entero y examinarlo cuidadosamente a posteriori.
La ventaja de tomar solamente lo que se necesite es que resulta más barato, rápido y menos caro que copiar contenidos enteros. En algunos casos es suficiente solamente con tomar los ficheros de actividad y los datos no borrados, en cuyo caso un backup del sistema sería suficiente.
Hay además un riesgo de que el sistema haya sido modificado con el fin de ocultar o destruir las evidencias (por ejemplo, usando unrootkit). Por ejemplo, si un investigador busca ficheros log en una computadora, puede haber ficheros logs borrados en el espacio libre que pueden serle útiles. Cuando se toman solo unos pocos ficheros es necesario documentar el proceso meticulosamente y registrar los ficheros en su estado original. Por ejemplo, obteniendo un listado completo de los ficheros con sus características asociadas como los nombres de ruta,s**ellos de tiempo**, tamaños y valores MD5.
Dados los riesgos y el esfuerzo de tomar solo unos pocos ficheros, en la mayoría de los casos es recomendable adquirir el contenido completo de un disco ya que un investigador raramente sabe a priori lo que contieneuna computadora. Antes de copiar datos de un disco es recomendable calcular el valor MD5 del disco original para compararlo luego con sus copias y así demostrar que son idénticas.
Cuando se toma el contenido completo de una computadora se debe hacer unacopia bit a bit, en lo que llamaremos una imagen forense, es decir, una copia exacta. Una imagen forense duplica todo lo que contenga un cluster de disco, incluyendo el “slack space” y otras areas de la superficie del disco, mientras que con otros métodosde copia de ficheros solamente se duplica el fichero y se deja el slack space atrás.
En cualquier dato, la evidencia digital se pierde si no se realiza una copia bit a bit. Por supuesto, esto solo nos concierne si el slack space puede contener información importante. Si solamente necesitamos la información que contiene un fichero y no se requiere el slack space, una copia del fichero sería suficiente.
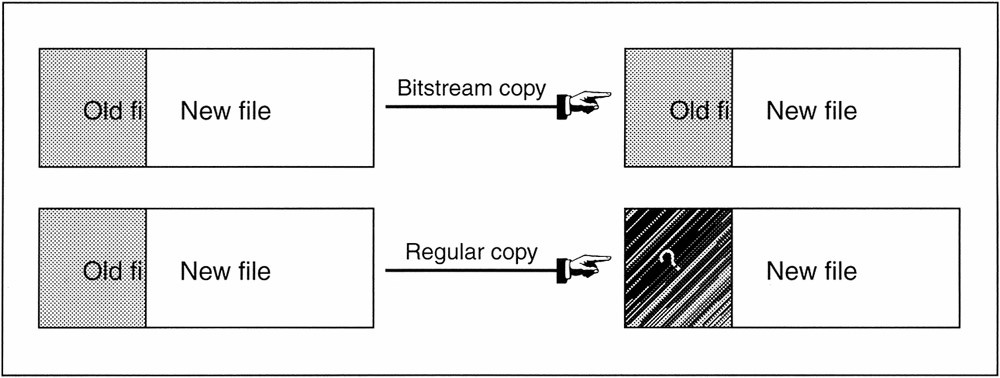
Figura: Comparación entre una copia normal y una bit a bit.
La mayoría de las herramientas pueden interpretar copias bit a bit creadas usando la herramienta EnCase (que se verá más adelante) y con el comando UNIX ‘dd’, haciéndolos a ambos los estándares ‘de facto’. “Safeback” es otro formato de ficheros comun perosolamente se usa en la policía. EnCase y Safeback incluyen información adicional en sus ficheros para comprobar su integridad. En todo caso hay una ley empírica en la recolección de evidencias digitales que siempre se debería recordar:
Ley empírica de Rec**olección de Evidencias y Conservación:**Si solamente haces una copia de la evidencia digital, esa evidencia será dañada o se perderá completamente.
De modo que siempre se deben hacer dos o más copias de la evidencia digital y comprobar que al menos una delas copias se realiza correctamente y puede ser accedida desde otra computadora.
Es muy importante guardar la copia digital en discos completamente limpios. Si se guarda en un disco que ya tenía algunos datos (por ejemplo, un disco duro usado), los datosantiguos pueden quedar en el slack space, contaminando así la evidencia. De modo que es una buena práctica usar un programa que escriba un patrón determinado en el disco (por ejemplo, 00000000) y verifique que este patrón se escribió en todos los sectores.
Como regla general, una computadora que se use para almacenar y analizar evidencias digitales no debería estar conectado a Internet. Existe el riesgo de que alguien gane acceso no autorizado a la evidencia.
Cuando se quiere extraer una imagen de una computadora se debe hacer con la mínima alteración posible para la misma. Una forma de hacerlo es introduciendo un disco boot preparado con las herramientas para extraer la imagen y arrancar la máquina con él. En algunos casos no es posible o deseable arrancar la máquina sospechosa, por lo que la mejor alternativa es quitar el/los disco/s duro/s de la computadora y ubicarlo en otra más segura, o insertarlo en un sistema especial de recolección de evidencias para su procesamiento. Los dispositivos de duplicación de Hardware como los fabricados por Intelligent Computer Solutions y Logicube son útiles para copiar datos de una unidad IDE o SCSI en otra.
Recuerde que a menudo es posible preguntar al dueño o administrador del sistema por ejemplo, si los datos estan encriptados. Estas personas deberían poder facilitarnos el acceso a ellos.
Técnicas de adquisición de datos
Hay tres técnicas principales que podemos usar para copiar datos del sistema sospechoso a un sistema seguro:
- La primera técnica usa la red para copiar datos desde el sistema sospechoso a un servidor seguro. Esta técnica puede usarse para adquisiciones en vivo o postmortem. La forma más fácil para llevarlo a cabo es usando la herramienta “netcat”, que puede actuarcomo cliente y como servidor. El servidor seguro ejecuta netcat con la opción “-l” para poner netcat en modo escucha. Un número de puerto es asignado usando la opción “-p”. Esto provoca que netcat escuche del puerto especificado y copie cualquier dato recibido en la pantalla. Úsese la redirección para guardar los datos en un fichero. Por ejemplo, para escuchar del puerto 9000 y guardar a fichero.out, usaríamos:
nc –l –p 9000 > fichero.out
Un método alternativo de copiar datos sobre la red es montar una unidad de red. Usando Samba o NFS, una unidad en el servidor seguro puede ser montada y los datos copiados en ella.
- Las otras dos técnicas de adquisición requieren una extracción física de las unidades. En un caso, el disco es extraido desde el sistema sospechoso y ubicado en un sistema seguro. En el otro, un nuevo disco es ubicado en el sistema sospechoso y es arrancado desde un CD-Rom seguro y el disco sospechoso es copiado en forma de imagen al disco nuevo. Esto es útil si hay hardware especial comoun disco RAID (Redundant Arrays of Inexpensive Disks).
Guía Básica
Hay algunas ideas clave que deben ser aplicadas en cualquier técnica de adquisición de datos. El objetivo es guardar el estado del sistema de modo que pueda ser analizado en un laboratorio. Cada situación será diferente y requerirá diferentes técnicas. Cuando usemos una herramienta deberemos tener en cuenta que siga las siguientes pautas:
Minimizar la escritura en el disco del sistema sospechoso: si se nos da la ocasión en que tengamos que elegir entre dos técnicas o herramientas, elegiremos la que escriba el mínimo de datos en el disco sospechoso. Utilizar herramientas que envían la salida a la salida estándar y canalizan los datos sobre la red a un servidor. Cualquier dato escrito en el sistema sospecho podría estar sobre una evidencia.
No fiarse de nada del sistema sospechoso:Si alguien tuvo permisos de administrador en un sistema pudo modificar desde el núcleo hasta los ejecutables. Deberemos usar nuestras propias versionescertificadas de los ejecutables cuando sea posible.
No instalar herramientas de adquisición de datos en el sistema:Úsese mejor un CD-Rom de herramientas certificadas cuando sea posible.
Mantener el Orden de volatilidad:El OOV (Order Of Volatility) fué documentado por Dan Farmer y Wietse Venema y se compone de las ubicaciones donde se almacenan los datos, ordenadas por la frecuencia en la que cambian sus valores. Podemos querer adquirir el que cambie primero más rápido,aunque algunos cambian demasiado rápido y pueden no sernos útiles (por ejemplo, los registros). La siguiente lista muestra el orden de volatilidad comenzando por el más volátil:
Conexiones de Red y Ficheros Abiertos
ProcesosoUsuarios activos
Disco duro
Calcular un valor hash fuerte para los datos adquiridos:Ejemplos de hashes fuertes son MD5, SHA-1 y SHA-2.
Documentar qué herramientas ejecutamos y las modificaciones que hacemos enel sistema:Podemos usar el comando “script” en UNIX para esto.
3.5 Examen y Análisis
3.5.1 Filtrado/Reducción de los datos para análisis
Antes de profundizar en los detalles del análisis de una evidencia digital, es necesaria una breve discusión sobre la reducción de los datos a analizar. Con el decremento del coste del almacenamiento de datos y el incremento del volumen de ficheros comerciales en sistemas operativos y aplicaciones software, los investigadores digitales pueden sentirse abrumados fácilmente por la inmensa cantidad de ficheros contenidos en un disco duro. Por consiguiente, los examinadores necesitan procedimientos para centrarse en los datos potencialmente útiles. El proceso de filtrar los datos irrelevantes, confidenciales o privilegiados incluye:
Identificar ficheros válidos del SSOO y otras entidades que no tienen relevancia para la investigación.
Enfocar la investigaciónen los datos más probablemente creados por el usuario.
Gestionar ficheros redundantes, que es particularmente útil cuando se trata con cintas de respaldo.
Otras técnicas menos metódicas de reducción de datos como búsqueda de cadenas específicas de textoo extraer solo ciertos tipos de ficheros, puede no solo hacernos perder pistas importantes, sino que puede dejar al investigador en un mar de datos superfluos. En resumen, una reducción de datos cuidadosa generalmente permite un análisis más eficiente y minucioso.
3.5.2 Búsqueda y recopilación de información
La siguiente guía esta basada en [3] y sirve para ayudar a los investigadores a identificar lás búsquedas más comunes de un análisis forense según su categoría específica de delito. La guía también ayudará a determinar el alcance del análisis que será realizado.
3.5.2.1 DELITOS CONTRA PERSONAS
Investigación de Muerte
Libretas de direcciones
Diarios
E-mail/notas/cartas
Registros de bienes/financieros
Imágenes
Logs de actividad en internet
Documentos legales y testamentos
Registros médicos
Registros telefónicos
Violencia Domestica
Libretas de direcciones
Diarios
E-mail/notas/cartas
Registros de bienes/financieros
Registros médicos
Registros telefónicos
Amenazas/Acoso por E-mail
Libretas de direcciones
Diarios
E-mail/notas/cartas
Registros de bienes/financieros
Imágenes
Logs de actividad en internet
Documentos legales
Registros telefónicos
Investigación de fondo sobrela víctima (posibles motivos, amigos, enemigos, etc)
3.5.2.2 DELITOS SEXUALES
Abuso/Explotación Infantil (Pornografía infantil)
Logs de chat
Marcas de tiempo en ficheros
Software de camara digital
E-mail/notas/cartas
Juegos
Software de edición y visionado de imágenes
Imágenes/Videos
Logs de actividad en internet
Directorios creados por el usuario y nombres de fichero que clasifican imágenesProstitución
Libretas de direcciones
Biografías
Agendas
Bases de datos de clientes/registros
E-mail/notas/cartas -Identificación falsa
Registros de bienes/financieros
Logs de actividad en internet
Registros médicos
Publicidad en páginas de la web
3.5.2.3 FRAUDES/OTROS DELITOS FINANCIEROS
Fraude en subastas (Online)
Datos de cuentas relativos a sitios de subastas
Software de contabilidad y ficheros de datos asociados
Libretas de direcciones
Calendario
Logs de chat
Logs de actividad en internet
Ficheros históricos/caché de explorador de internet
Información de comprador/Datos de tarjeta de crédito
Bases de datos
Software de cámara digital
Ficheros de imagen
E-mail/notas/cartas
Registros de bienes/financieros
Software de acceso a instituciones financieras online
Registros/Documentos de “testimonios”
Registros telefónicos
Intrusión en un computador
Libretas de direcciones
Ficheros de configuración
E-mail/notas/cartas
Programas ejecutables
Logs de actividad en internet
Dirección de Internet (IP) y nombre de usuario
Logs de IRC
Código fuente
Ficheros de texto (nombres de usuario y password)38
Fraude económico (Incluyendo Fraude Online y Falsificación de dinero)
Libretas de direcciones
Agendas
Imágenes de monedas
Imágenes de cheques, monedas/billetes o giros postales
Copiadoras de bandas magnéticas
Información de comprador/Datos de tarjeta de crédito
Bases de datos
E-mail/notas/cartas
Formularios de transacciones financieras falsos
Identificación falsa
Registros de bienes/financieros
Imágenes de firmas
Logs de actividad en internet
Software de acceso a instituciones financieras online
Extorsión
Marcas de tiempo de ficheros
E-mail/notas/cartas
Logs históricos
Logs de actividad en internet
Ficheros temporales de internet
Nombres de usuario
Apuestas ilegales/Juego
Libretas de direcciones
Agendas
Bases de datos del cliente y registros de jugador
Información de cliente/Datos de tarjeta de crédito
Dinero electrónico
E-mail/notas/cartas
Registros de bienes/financieros
Logs de actividad en internet
Imágenes de los jugadores
Software de acceso a instituciones financieras online
Estadísticas de apuestas en deportes
Robo de identidad
Herramientas de hardware y softwareoBackdrops
Generadores de tarjetas de créditooLectores/Grabadores de tarjetas
Cámaras digitales
Escaners
Plantillas de identificaciónoCertificados de nacimiento
Cheques
Imágenes digitales para identificación por fotografía
Permisos de conduciroFirmas electrónicasoRegistros de vehículos ficticiosoDocumentos sobre seguros de automóvilesoFirmas escaneadasoTarjetas de seguridad social
Actividad en internet relacionada con el robo de IdentidadoE-mails y envíos a grupos de noticiasoDocumentos borradosoPedidos onlineoInformación de comercio onlineoFicheros del sistema y el slack space de ficherosoActividad en la web en sitios de falsificación
InstrumentosnegociablesoCheques comercialesoCheques bancariosoCheques individualesoCheques de viajerooDinero falsificadooNúmeros de tarjeta de créditooDocumentos ficticios de juiciosoVales de regalo ficticiosoDocumentos ficticios de préstamosoRecibos ficticios de ventasoGiros postalesoDocumentos de transferencia de mercancíasoDocumentación de transferencia de vehículos
40
Narcoticos
Libretas de direcciones
Agendas
Bases de datos
Fórmulas/Recetas de drogas
E-mail/notas/cartas -Identificación falsa
Registros de bienes/financieros
Logs de actividad en internet
Imágenes/Plantillas de formularios de recetas médicas
Piratería de Software
Logs de chat
E-mail/notas/cartas
Ficheros de imagen de certificados software
Números de serie
Utilidades e información sobre crackeo de software
Directorios creados por el usuario y nombres de ficheros del software clasificado con copyright.
Fraude de Telecomunicaciones
Software de clonación
Bases de datos de clientes/registros
Registros con el par: Número de serie electrónicos/Número de identificación de móvil
E-mail/notas/cartas
Registros de bienes/financieros
Manuales de “how to phreak” (phreak:prenombre que se le da una persona que penetra de manera ilegal a la red de teléfonos o de computadoras)
Actividad de internet
Registros telefónicos
En una escena física, se debe buscar material de duplicación y empaquetado. La siguiente información debería ser documentada cuando esté disponible:
Sumario del caso
Direcciones de internet(IP)
Listas de palabras clave
Apodos de internet (Nicknames)
Passwords
Puntos de contacto
Documentos de soporte
Tipo de delito
3.5.3 Cuadro Resumen
| A | Pornografía Infantil | F | Fraude subastas online | K | Robo de identidad | |
|---|---|---|---|---|---|---|
| B | Prostitución | G | Intrusión | L | Narcóticos | |
| C | Muerte | H | Fraude económico | M | Piratería | |
| D | Violencia doméstica | I | Extorsión | N | Fraude | de |
| E | Amenazas/Acoso | J | Apuestas ilegales |
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Información General: | ||||||||||||||
| Bases de datos | ||||||||||||||
| Email/Notas/Cartas | ||||||||||||||
| Registros Financieros | ||||||||||||||
| Registros Medicos | ||||||||||||||
| Registros Telefónicos | ||||||||||||||
| Información Específica: | ||||||||||||||
| Datos sobre cuentas | ||||||||||||||
| Softwarede | ||||||||||||||
| Libreta de direcciones | ||||||||||||||
| Backdrops | ||||||||||||||
| Biografias | ||||||||||||||
| Certificadosde | ||||||||||||||
| Agendas | ||||||||||||||
| Logs de Chat | ||||||||||||||
| Imagenes de cheque, moneda o giro postal | ||||||||||||||
| Tarjetasde comprobación de | ||||||||||||||
| Software de clonación | ||||||||||||||
| Ficherosde | ||||||||||||||
| Dinero falso | ||||||||||||||
| Generadoresde | ||||||||||||||
| Números de tarjetas de crédito | ||||||||||||||
| Lectores/Grabadores de tarjetas de crédito |
| Copiadores de bandas magnéticas | ||||||||||||||
| Basesdedatosde | ||||||||||||||
| Información de clientes/Tarjetas de | ||||||||||||||
| Marcas de tiempo | ||||||||||||||
| Diarios | ||||||||||||||
| Software/Imágenes de cámaras digitales | ||||||||||||||
| Licencia de conducir | ||||||||||||||
| Recetas de drogas | ||||||||||||||
| Dinero electrónico | ||||||||||||||
| Firmas electrónicas | ||||||||||||||
| Documentos borrados | ||||||||||||||
| Registros con el par ESN/MIN de móviles | ||||||||||||||
| Programas ejecutables | ||||||||||||||
| Formularios falsos de | ||||||||||||||
| Identificación falsa | ||||||||||||||
| Documentos falsos de juicios | ||||||||||||||
| Vales de regalo falsos | ||||||||||||||
| Documentos falsos de préstamos | ||||||||||||||
| Recibos falsos | ||||||||||||||
| Registros de vehículos falsos | ||||||||||||||
| Juegos | ||||||||||||||
| Edición y Visionado de imágenes | ||||||||||||||
| Logs históricos |
| Manuales “phreak” | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Imágenes | ||||||||||||||
| Imágenes de firmas | ||||||||||||||
| Ficherosde | ||||||||||||||
| Reproductoresde imagenes | ||||||||||||||
| Logs de actividad de internet | ||||||||||||||
| Históricos/Cachéde los navegadores | ||||||||||||||
| Nombre Usuario / IP | ||||||||||||||
| Logs de IRC | ||||||||||||||
| Documentos legales y testamentos | ||||||||||||||
| Videos | ||||||||||||||
| Software de acceso a bancos online | ||||||||||||||
| Pedidos online e info. | ||||||||||||||
| Imágenes de recetas médicas | ||||||||||||||
| Documentosde | ||||||||||||||
| Firmas escaneadas | ||||||||||||||
| Números de serie | ||||||||||||||
| Tarjetas de Seguridad Social | ||||||||||||||
| Utilidades/Información de crackeo de software | ||||||||||||||
| Código fuente | ||||||||||||||
| Estadísticasde | ||||||||||||||
| Documentos de transferencia de | ||||||||||||||
| Fichreos del sistema y slack space de ficheros | ||||||||||||||
| Ficheros temporales de internet | ||||||||||||||
| Nombres de usuario | ||||||||||||||
| Directorios creados por el usuario y nombres de ficheros clasificados como | ||||||||||||||
| Directorios creados por el usuario y nombres de ficheros de imágenes | ||||||||||||||
| Docuementaciónde | ||||||||||||||
| Búsqueda de fondo de la víctima | ||||||||||||||
| ActividadWeben | ||||||||||||||
| Publicidad de páginas web |
3.5.4 Técnicas de extracción de información
La presente información se ha extraido de [1] y [7]
3.5.4.1 ORGANIZACIÓN DE UN SISTEMA DE FICHEROS
La motivación de un sistema de ficheros es medianamente simple:Las computadoras necesitan un método para el almacenamiento a largo plazo y la recuperación de datos.Los sistemas de ficheros proveen un mecanismo para que usuarios almacenen datos en una jerarquía de archivos y directorios.Un sistema de ficheros constade datos de su estructura y de los datos de usuario, que están organizados de tal manera que la computadora sepa donde encontrarlos.En la mayoría de los casos,el sistema de ficheros es independiente de cualquier computadora específica.
Un sistema de ficheros se estructura en varias capas o categorías que pasamos a enumerar a continuación:
La categoría desistema de ficheroscontiene la información general del mismo. Todos los sistemas de ficheros tienen una estructura general para ellos, pero cada instancia de un sistema de ficheros en única, ya que tiene un tamaño único y puede ser modificada y adaptada para su uso específico.
La categoríacontenidocontiene los datos de los que se compone el contenido de un fichero. La mayoría de los datos de un sistema de ficheros atienden a esta categoría, y se organizan en una colección de contenedores de tamaño estándar. Cada sistema de ficheros asigna un nombre diferente a estos contenedores, como clusters o bloques, aunque nosotros usaremos_Unidad de datos_para generalizar el término.
La categoríameta-datoscontiene los datos que describen un fichero. Esta categoría contiene información de donde se almacenan los ficheros, como de grandes son, las últimas fechas de lectura o escritura sobre él, e información de control de acceso. Nótese que esta categoría no tiene el contenido de un fichero o su nombre. Ejemplos de estructuras de datos en esta categoría incluyen las entradas de directorio FAT, las entradas en la MFT (Master File Table) de un sistema NTFS, y las estructuras de inodos de UFS y Ext3.
La categoríanombre de fichero, o categoría interfaz humana, contiene los datos que relacionan un nombre a cada fichero. En la mayoría de los sistemas de ficheros, esos datos están almacenados en el contenido de un directorio y hay una lista de nombres de ficheros con su correspondiente dirección de meta-datos. Esta categoría es similar a un nombre de host en una red. Los dispositivos de red se comunican entre ellos usando una dirección IP, que es difícil de recordar parala gente. Cuando un usuario introduce el nombre de host de una computadora remota, la computadora local debe traducir el nombre a una dirección IP antes de que comience la comunicación.
La categoríaaplicacióncontiene datos que proporcionan características especiales. Esos datos no se necesitan durante el proceso de lectura o escritura de un fichero y, en la mayoría de los casos, no necesitan ser incluidos en la especificación del sistema de ficheros. Esos datos están incluidos en la especificación porque puede ser más eficiente implementarlos en el sistema de ficheros en lugar de en un fichero normal. Ejemplos de datos en esta categoría incluyen las estadísticas de cuota del usuario y la bitácora de un sistema de ficheros. Estos datos pueden ser útiles durante una investigación, pero pueden ser falsificados más fácilmente que otros datos, ya que no se necesitan para escribir y leer un fichero.
3.5.4.2 CATEGORÍA DE SISTEMA DE FICHEROS
La categoría de sistema de ficheros contiene los datos generales que nos permiten identificar como de único es el sistema de ficheros y donde se encuentran otros datos importantes. En muchos casos, la mayoría de estos datos están situados en una estructurade datos estándar en los primeros sectores del sistema de ficheros, de forma similar a tener un mapa de un edificio en el recibidor del mismo. Con esta información, los datos pueden ser localizados fácilmente.
El análisis de datos en la categoría de sistema de ficheros es necesario para todos los tipos de análisis de un sistema de ficheros, ya que es durante esta fase cuando se encuentra la localización de las estructuras de datos de otras categorías. Por lo tanto, si alguno de estos datos se corrompe ose pierde, se complica el análisis en otras categorías porque deberíamos encontrar una copia de seguridad o adivinar donde se encuentran estas estructuras. Además de la información general, el análisis de esta categoría puede mostrar la versión de un sistema de ficheros, su etiqueta (nombre), la aplicación que lo creó y la fecha de creación. Hay pocos datos en esta categoría de forma que un usuario debería poder cambiar o verla sin la ayuda de un editor hexadecimal. En muchos casos, los datos no generales que se encuentran en esta categoría son considerados como intrascendentes y podrían no ser exactos.
Técnicas de análisis
Los datos de esta categoría son normalmente valores individuales e independientes. Por lo tanto no hay mucho que hacer con ellos, salvo mostrarlos o usarlos en una herramienta. Si se están recuperando datos a mano, la información que contiene puede ser útil. Si se trata de determinar en que computadora fue creado el sistema de ficheros, un ID de volumen o su versión puede sernos de utilidad. Las estructuras de datos de esta categoría frecuentemente tienen valores no usados y direcciones de almacenamiento que podrían esconder pequeñas cantidades de datos. Un chequeo de la consistencia en esta categoría consiste en comparar el tamaño delsistema de ficheros con el tamaño del volumen en el que se encuentra. Si el volumen es más grande, los sectores que se encuentran después del sistema de ficheros son llamados “volume slack” y puede ser usado para ocultar datos.
3.5.4.3 CATEGORÍA CONTENIDO
La categoría contenido incluye las direcciones de almacenamiento donde se alojan los ficheros y directorios de forma que puedan guardar datos. Los datos en esta categoría están organizados normalmente dentro de grupos del mismo tamaño, que llamaremos unidades de datos, que son por ejemplo los clusters o bloques. Una unidad de datos tiene un estado: asignado o no asignado. Normalmente hay algunos tipos de estructuras de datos que mantienen el estado de cada unidad de datos.
Cuando se crea un nuevo fichero o un fichero existente se hace mas grande, el Sistema Operativo busca una unidad de datos no asignada y la asigna a un fichero. Cuando se borra un fichero, las unidades de datos asignadas al fichero se ponen con estado no asignado y pueden asignarse a nuevos ficheros. La mayoría de los SSOO no limpian el contenido de la unidad de datos cuando se borra un fichero, sino que simplemente cambian su estado a no asignado. Este “borrado seguro” solo puede hacerse con herramientas especializadas o con SSOO que provean esta habilidad.
El análisis de esta categoría de contenido esta pues enfocada a recuperar datos perdidos y hacer búsquedas de datos a bajo nivel. Debido a la inmensa cantidad de datos que se pueden encontrar en esta categoría, normalmente no se analiza a mano. Como referencia, si un investigador examinara un sector de 512 bytes en cinco segundos, para analizar 40 GB necesitaría 388 días trabajando durante 12 horas diarias.
Información General
Veamos a continuación como se direccionan las unidades de datos, como se asignan y como se manejan las unidades de datos dañadas.
Direccionamiento lógico del sistema de ficheros
Un volumen es una colección de sectores direccionables que un SSOO o una aplicación pueden usar paraalmacenar datos. Los sectores en un volumen no necesitan ser consecutivos en un dispositivo de almacenamiento físico. En lugar de eso,necesitan sólo dar la impresión que lo están.Un disco duro es un ejemplo de un volumen que se encuentra organizado en sectores consecutivos.Un volumen también puede ser el resultado de ensamblar y la combinación de volúmenes más pequeños.
Un sector puede tener múltiples direcciones, cada una desde una perspectiva diferente. Cada sector tiene una dirección relativa al inicio del dispositivo de almacenamiento, que es lo que llamamos una dirección física. Los sistemas de volumen crean volúmenes y asignan direcciones lógicas de volumen que son relativas al inicio del volumen.
Los sistemas de ficheros usan las direcciones lógicas de volumen, pero además asignan direcciones lógicas de sistemas de ficheros, ya que agrupan varios sectores consecutivos para formar una unidad de datos. En la mayoría de los sistemas de ficheros, cada sector en el volumen es asignado a una direcciónlógica de sistema de ficheros. Un ejemplo de un sistema de ficheros que no asigna una dirección lógica de sistema de ficheros a cada sector es FAT.
Estrategias de asignación
Un SSOO puede usar diferentes estrategias para asignar unidades de datos. Normalmente un SSOO asigna unidades de datos consecutivas, pero esto no es siempre posible. Cuando un fichero no tiene unidades de datos consecutivas se dice que está fragmentado.
Una primera estrategia busca una unidad de datos disponible empezando por la primera unidad de datos del sistema de ficheros. Después de que una unidad de datos ha sido asignada usando esta estrategia y se necesita una segunda unidad de datos, la búsqueda comienza de nuevo en el inicio del sistema de ficheros. Este tipo de estrategia puede fácilmente producir ficheros fragmentados ya que el fichero no es asignado de una pieza. Un SSOO que usa esta estrategia suele sobrescribir más a menudo los datos de ficheros borrados al inicio del sistema de ficheros. Por tanto tendremos más suerte recuperando contenidos borrados del final del sistema de ficheros.
Una estrategia similar está disponible; ésta inicia su búsqueda con la unidad de datos que fue más recientemente asignada en lugar de al comienzo. Este algoritmo es más balanceado para recuperar datos ya que las unidades de datos en el inicio del sistema de ficheros no son reasignadas hasta que las unidades de datos de final hayan sido reasignadas. Esto es así porque no se buscan unidades de datos libres desde el inicio hasta que no se haya llegado al final del sistema de ficheros.
Otra estrategia es la del mejor ajuste, que busca unidades de datos consecutivas que puedan alojar la cantidad de datos necesaria. Esta estrategia trabaja bien si se conocen cuantas unidades de datos necesitará un fichero, pero cuando el fichero crece, las nuevas unidades de datos que se necesitan pueden no ser consecutivas y tendríamos un fichero fragmentado.
Cada SSOO puede elegir una estrategia de asignación para un sistema de ficheros. Algunos sistemas de ficheros especifican que estrategia debería usarse, pero no existe ninguna manera para forzarlo. Debería pues probar la implementación de un sistema de ficheros antes de asumir que se esta usando la estrategia de la especificación.
Además de probar el sistema operativo para determinar su estrategia de asignación, se deberíaconsiderar la aplicación que crea el contenido. Por ejemplo, cuando se actualiza un fichero existente, algunas aplicaciones abren el fichero original, lo actualizan y guardan los nuevos datos sobre los originales. Otras aplicaciones pueden hacer una segunda copia del fichero original, actualizar esta copia y luego renombrar la copia de forma que se sobrescribe el fichero original. En este caso, el fichero se almacena en nuevas unidades de datos, ya que es parte de un nuevo fichero.
Unidades de datos dañad**as**
Muchos sistemas de ficheros tienen la habilidad de marcar una unidad de datos como dañada. Esto era necesario en los discos duros más antiguos, que no tenían la capacidad de manejar errores. El sistema operativo debería detectar que una unidad de datos era mala y marcarla de forma que no se asignara a un fichero. En la actualidad los modernos discos duros pueden detectar un sector erróneo y reemplazarlo por uno de repuesto, de modo que no se necesita la funcionalidad del sistema de ficheros.
Es fácilesconder datos usando esta funcionalidad del sistema de ficheros, si existe (solo está en discos duros antiguos). Muchas herramientas que prueban la consistencia de un sistema de ficheros no verifican que una unidad de datos que está marcada como dañada esté actualmente dañada. Por lo tanto, un usuario podría añadir manualmente una unidad de datos a la lista de dañadas y así esconder datos.
Técnicas de análisis
Ahora que hemos visto los conceptos básicos de la categoría contenido, vamos a ver como analizar los datos. Esta sección cubre diferentes técnicas de análisis que pueden ser usados cuando se buscan evidencias.
Visualizando las unidades de datos
Esta es una técnica usada cuando el investigador conoce la dirección donde puede estar la evidencia, tal como una asignada a un fichero especifico o una que tiene un especial significado. Por ejemplo, en muchos sistemas de ficheros FAT32, el sector 3 no es usado por el sistema de ficheros y está lleno de ceros. Es fácil esconder datos en este sector, ypor tanto, visualizando el contenido del sector 3 podemos ver si ha sido modificado si no esta lleno de ceros.
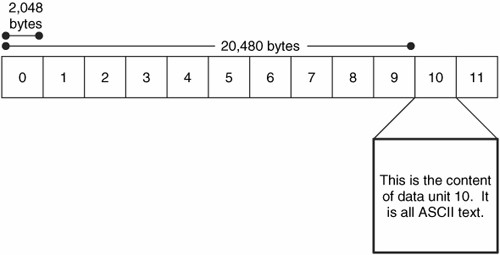
La teoría que encierra este tipo de análisis es simple. El investigador introduce la dirección lógica del sistema de ficheros de una unidad de datos y una herramienta calcula la dirección del byte o sector de la unidad de datos. La herramienta busca la localización y lee los datos. Por ejemplo considere un sistema de ficheros donde la unidad de datos 0 empieza en el byte con offset 0, y cada unidad de datos tiene 2 kb (2048 bytes). El offset de byte de cada unidad de la unidad de datos 10 está en el kb 20 (20480 bytes).
La teoría que encierra esto es simple. El investigador introduce la dirección lógica del sistema de ficheros de la unidad de datos y una herramienta calcula su dirección de byte o sector. La herramienta busca en esa ubicación y lee los datos. Por ejemplo, considérese un sistema de ficheros donde la unidad de datos 0 comienza en el desplazamiento de byte 0, y cada unidad de datos es de 2.048 bytes (2 kb). El desplazamiento de byte de la unidad de datos 10 será de 20.480 bytes (20 kb). Podemosver esto en la siguiente figura:
Contenido de la unidad de datos 10.
Hay muchas herramientas, como editores hexadecimales y herramientas de investigación que proveen esta función.
Búsqueda de cadenas
En la técnica anterior, conocíamos donde podía estar la evidencia. En esta técnica sabemos que el contenido que debería tener la evidencia, pero no sabemos donde está. Una búsqueda lógica del sistema de ficheros busca en cada unidad de datos un valor o frase específicos. Por ejemplo, podríamos buscar la frase “forense” o un valor específico de una cabecera de fichero. Ésta técnica suele usarse en la búsqueda de datos en la memoria de Intercambio (Swap), que suele ser un conjunto de datos en bruto sin metadatos ni nombres de fichero apuntando a ellos.
Esta técnica de búsqueda se ha llamado históricamente una búsqueda física ya que usa la ordenación física de los sectores. Esta búsqueda es precisa cuando se analiza un disco simple, pero en caso de sistemas que usen “disk spanning” o discos RAID, el orden de los sectores no es el orden físico.
Desafortunadamente, los ficheros no siempre alojan unidades de datos consecutivas y si el valor que estamos buscando se encuentra en dos unidades de datos no consecutivas de un fichero fragmentado, una búsqueda lógica en el sistema de ficheros no lo encontrará.
Estado de Asignación de Unidades de Datos
Si no conocemos la localización exacta de la evidencia, pero sabemos que no está asignada, podemos enfocar nuestra atención ahí. Algunas herramientas pueden extraer todas las unidades de datos no asignadas de la imagen de un sistema de ficheros a un fichero separado, y otras pueden restringir su análisis a solo las áreas no asignadas. Si extraemos solo los datos no asignados, la salida será una colección de datos en bruto sin estructura de sistema de ficheros, de modo que no se puede usar con una herramienta de análisis de sistema de ficheros.
Orden de asignación de las unidades de datos
Previamente hemos visto algunas estrategias que un sistema operativo puede usar cuando asigna unidades de datos. La estrategia que se use depende generalmente del SSOO; por consiguiente se encuentra en el área del análisis a nivel de aplicación. Por ejemplo, Windows ME puede usar una estrategia de asignación diferente para un sistema de ficheros FAT que Windows 2000, pero ambos producen un sistema de ficheros FAT válido.
Si el orden de asignación relativo de dos o más unidades de datos es importante, podemos considerar la estrategia de asignación del SSOO para ayudarnos a determinarlo. Esto es muy difícil, ya que requiere determinar la estrategia que usa el SSOO y necesitaremos examinar cada escenario que podríamos tener según el estado de las unidades de datos en un momento dado. Esto implica conocer información a nivel de aplicación. Esta técnica se usa durante la reconstrucción de eventos, lo cual ocurre después de que hayamos reconocida las unidades de datos como evidencias.
Pruebas de consistencia
Esta es una importante técnica de análisis para cada categoría de datos. Nos permite determinar si el sistema de ficheros esta en un estado sospechoso. Una prueba de consistencia en la categoría contenido usa datos de la categoría meta-datos y verifica quecada unidad de datos asignada tiene exactamente una entrada de meta-datos apuntando a ella. Esto se hace para prevenir que un usuario manipule manualmente el estado de asignación de una unidad de datos sin que esta tenga un nombre. Las unidades de datos asignadas que no tienen una correspondiente estructura de meta-datos se llaman huérfanas.
Otras pruebas examinan cada unidad de datos que se lista como dañada. Si tenemos una imagen de un disco duro que contiene sectores defectuosos, muchas de las herramientas de adquisición de datos llenarán los datos dañados con ceros. En este caso, las unidades de datos ubicadas en la lista de defectuosos deberían tener ceros en su interior.
Técnicas de borrado seguro
Ahora que sabemos como analizar datos en esta categoría, vamos a pasar a ver como un usuario puede hacernos la vida mas dura. La mayoría de las herramientas de borrado seguro operan en la categoría contenido y escriben ceros o datos aleatorios en las unidades de datos de un fichero asignado o de todas las unidades de datos.
El borrado seguro está siendo cada vez más común y una característica estándar en algunos sistemas operativos. Las que se construyen en los sistemas operativos son más efectivas a la hora de limpiar todos los datos (poner todos los bits a 0). Las aplicaciones externas frecuentemente dependen del SSOO para actuar de cierto modo; por tanto, no pueden ser tan efectivos. Por ejemplo, hace muchos años había una herramienta basada en Linux que escribía ceros en una unidad de datos antes de que se estableciera como no asignada, pero el SSOO no escribía inmediatamente ceros en el disco. Más tarde el SSOO vería que la unidad estaba no asignada y por tanto no se tomaría la molestia de escribir ceros en ella. De manera semejante, muchas herramientas asumen que cuando escriben datos en un fichero, el SSOO usará las mismas unidades de datos. Un SSOO puede elegir asignarle otras unidades de datos y, en tal caso, el contenido del fichero aun existirá.
La detección del uso de herramientas de borrado seguro en esta categoría puede ser difícil. Obviamente, si una unidad de datos no asignada contiene ceros o valores aleatorios, podemos sospechar de una herramienta de este tipo. Si la herramienta escribe valores aleatorios o hace copias de otras unidades de datos existentes, la detección es virtualmente imposible sin una evidencia a nivel de aplicación de que se usó una de estas herramientas. Por supuesto, si se encuentra una herramienta de borrado seguro en el sistema, podemos hacer pruebas para ver si seusó cual fue su último tiempo de acceso. También se pueden encontrar copias temporales de los archivos si estos fueron borrados explícitamente.
3.5.4.4 CATEGORÍA META-DATOS
La categoría meta-datos es donde residen los datos descriptivos. Aquí podemos encontrar, por ejemplo, el último tiempo de acceso y las direcciones de las unidades de datos que un fichero tiene asignadas. Hay pocas herramientas que se identifiquen como de análisis de meta-datos. En su lugar, vienen combinadas con el análisis de la categoría de nombre de fichero.
Muchas estructuras de meta-datos son almacenadas en una tabla estática o dinámica, y cada entrada tiene una dirección. Cuando un fichero es borrado, la entrada de metadatos se modifica al estado no asignado y el SSOO puede limpiar algunos valores de la entrada.
El análisis en esta categoría está enfocado a determinar más detalles sobre un fichero específico o buscar un fichero que cumple ciertos requerimientos. Esta categoría tiende a tener más datos intrascendentes que otras categorías. Por ejemplo, la fecha del último acceso o el número de escrituras pueden no ser precisos. Además, un investigador no puede concluir que un usuario tuvo o no permisos de lectura de un fichero sin otras evidencias de otras categorías.
Información General
En esta sección miraremos los conceptos básicos de la categoría meta-datos. Veremos otro esquema de direccionamiento, “slack space”, recuperación de ficheros borrados, ficheros comprimidos y encriptados.
Dirección lógica de fichero
Previamente hemos visto como una unidad de datos tiene una dirección lógica de sistema de ficheros. Una dirección lógica de fichero de una unidad de datos es relativa al inicio del fichero al cual está asignado. Por ejemplo, si un fichero tiene asignadas dos unidades de datos, la primera unidad de datos debería tener una dirección lógica de fichero de 0, y el segundo una dirección de 1. El nombre o dirección de metadatos para el fichero es necesaria para hacer una única dirección lógica de fichero.
Slack Space
El “Slack space” es una de las palabras de moda en el análisis forense que mucha gente ha oído alguna vez. El Slack space ocurre cuando el tamaño de un fichero no es múltiplo del tamaño de la unidad de datos. Un fichero debe tener asignada una unidad de datos completa aunque muchas veces solo use una pequeña parte. Los bytes no usados al final de la unidad de datos es lo que se llama Slack space. Por ejemplo, si un fichero tiene 100 bytes, necesita tener asignada una unidad completa de 2048 bytes. Los 1948bytes que sobran sería slack space.
Este espacio es interesante porque las computadoras son perezosas. Algunas de ellas no limpian los bytes no usados, de modo que el slack space contiene datos de ficheros anteriores o de la memoria. Debido al diseño de la mayoría de las computadoras, hay dos áreas interesantes en el Slack space. La primera área se ubica entre el final del fichero y el final del sector en el que el fichero termina. La segunda área se encuentra en los sectores que no contienen contenido delfichero. Hay dos áreas distintas porque los discos duros están basados en bloques y solo pueden ser escritos en sectores de 512 bytes. Siguiendo el ejemplo anterior, el SSOO no puede escribir solo 100 bytes en el disco, sino que debe escribir 512. Por lotanto, necesita rellenar los 100 bytes con 412 bytes de datos. Esto se puede comparar al envío por correos de un objeto en una caja. El espacio sobrante hay que rellenarlo con algo hasta completar la caja.
El primer área del slack space es interesante porque el SSOO determina con que rellenar el contenido. El método obvio es rellenar el sector con ceros y esto es lo que la mayoría de SSOO hacen. Esto es como rellenar la caja anterior con papel de periódico.Algunos SSOO antiguos llamados DOS y más tarde Windows, rellenaban el sector con datos de la memoria. Esto es como rellenar la caja con copias de tu declaración de hacienda. Este área de slack space se llamó RAM slack, y ahora normalmente es rellenada conceros. El RAM slack podía revelar passwords y otros datos que se supone que no deberían estar en el disco.
La segunda área del slack space se compone de los sectores en desuso de una unidad de datos. Esta área es interesante porque los SSOO limpian los sectores y otros los ignoran. Si se ignora, los sectores contendrán datos del fichero al que pertenecían previamente.
Consideremos un sistema de ficheros NTFS con clusters de 2048 bytes y sectores de 512 bytes, con lo que cada clúster se compone de 4 sectores. Nuestro fichero tiene 612 bytes, de modo que usa el primer sector entero y 100 bytes más del segundo sector. Los 412 bytes que sobran del segundo sector son rellenados con los datos que elija el SSOO. El tercer y cuarto sectores pueden ser limpiados con ceros por el SSOO, o pueden no tocarse conservar los datos de un fichero borrado. Podemos ver esto en la siguiente figura donde las áreas en gris representan el contenido del fichero y el espacio blanco es el slack space.
Slack space de un fichero de**612 bytes en un cluster de 2048 bytes donde cada sector tiene 512 bytes.**
Una analogía común para el slack space es el video VHS. Supongamos una cinta
VHS de 60 minutos. Una noche alguien graba 60 minutos de un episodio de una serie de TV. En otra ocasión decide ver de nuevo el episodio y al final rebobina la cinta. Otra noche graba 30 minutos de otro programa de TV. En ese punto la cinta queda “asignada” a este programa de TV, ya que el contenido anterior se borró, pero aún quedan 30 minutos de la serie de TV en el espacio sobrante de la cinta.
Recuperación de ficheros basada en los Meta-datos
En algunos casos, se puede querer buscar evidencias en los ficheros borrados. Hay dos métodos principales para recuperar ficheros borrados: basados en meta-datos y basados en aplicación. Las segundas se mencionan en apartados posteriores y por tanto vamosa hablar de la primera aquí. La recuperación basada en meta-datos trabaja cuando los meta-datos del fichero borrado aun existen. Si el meta-dato fue borrado o si la estructura de meta-datos se reasignó a un nuevo fichero, se necesitará el apoyo de las técnicas basadas en aplicación.
Después de encontrar la estructura de meta-datos del fichero, recuperarlo es fácil. No es diferente de leer los contenidos de un fichero asignado. Se necesita ser cuidadosos a la hora de hacer recuperación basada en meta-datosya que las estructuras de meta-datos y las unidades de datos podrían no estar sincronizadas, de modo que la unidad de datos esté asignada a nuevos ficheros.
Esto es similar a enlazar a una persona con un hotel en el cual haya estado. Después de que la persona registre la salida,todavía puede haber un registro de que él estuvo en el cuarto 427,pero la condición del cuarto de ese punto de adelante puede no tener nada que ver con él, ya que otros clientes la han podido usar.
Cuando se recuperan archivosborrados, puede ser difícil detectar cuando una unidad de datos ha sido reasignada. Vamos a considerar una secuencia de asignaciones y borrados. La estructura de meta-datos 100 tiene asignada la unidad de datos 1000 y guarda los datos en ella. El fichero cuya entrada de meta-datos es la 100 es borrado y por tanto esta entrada y la unidad de datos 1000 pasan al estado de no asignadas. Un nuevo fichero es creado en la estrada de meta-datos 200, y se le asigna la unidad de datos 1000. Más tarde, ese fichero estambién borrado. Si analizamos este sistema, encontraremos dos entradas de meta-datos no asignadas que tienen la misma dirección de unidad de datos.
La secuencia de estados donde los ficheros son asignados y borrados y en C no está claro de donde vien**en los datos de la unidad de datos 1000.**
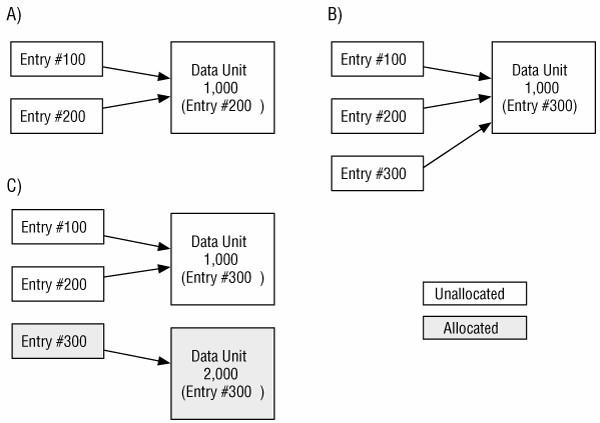
Necesitamos determinar cual de las entradas se asignó al fichero más recientemente.
Un método para hacer esto es usar la información temporal de cada entrada (u otrosdatos externos), pero puede que no seamos capaces de asegurarlo. Otro método es usar el tipo de fichero, si el meta-dato almacena esa información. Por ejemplo, la entrada de meta-datos 200 podría haber pertenecido a un directorio, de modo que podríamos analizar el contenido de la unidad 1000 para ver si tiene el formato de un directorio.
Aunque podamos determinar que la entrada 200 tuvo asignada la unidad de datos después que la 100, no sabemos si la entrada 200 fue la ultima entrada que lo tuvo asignado.Para ver esto, considere una entrada 300 asignada a la unidad de datos 1000 después de que se estableciera la entrada 200 a no asignada. Ese fichero es luego borrado y podemos ver el resultado en la figura B, donde hay tres entradas no asignadas que tienen la misma dirección de unidad de datos.
A continuación, un nuevo fichero fue creado y la entrada 300 fue reasignada a una nueva unidad de datos 2000. Si analizáramos el sistema en este estado no encontraríamos ninguna evidencia en la entrada 300, sino enla 100 y la 200, lo cual se muestra en la figura C.
El objetivo de este ejemplo es mostrar que aunque una estructura de meta datos no asignada aun contenga las direcciones de unidades de datos, es muy difícil determinar si el contenido de la unidad de datos corresponde a ese fichero o un fichero fue creado después de que se estableciera la estructura de meta-datos como no-asignada. Se puede verificar que una recuperación de fichero fue precisa intentando abrirla en la aplicación que pensemos que la creó.Por ejemplo, si recuperamos un fichero “datos.txt” lo podemos abrir con un editor de textos Si a un nuevo fichero se le asigna la unidad de datos de un fichero borrado y escribe datos en ella, la estructura interna del fichero puede estar corrupta y un visor podría no abrirla.
Ficheros comprimidos y Sparse
Algunos sistemas de ficheros permiten que los datos se almacenen en un formato comprimido de forma que ocupen menos unidades de datos en el disco. Para lo ficheros, la compresión puede ocurrir en al menos tres niveles. En el nivel más alto es cuando los datos de un formato de fichero son comprimidos. Por ejemplo, un fichero JPEG es un ejemplo de esto donde los datos que almacenan la información de la imagen son comprimidos, pero no así la cabecera. El siguiente nivel es cuando un programa externo (winzip, winrar, gzip,...) comprime un fichero entero y crea un nuevo fichero. El fichero comprimido debe ser descomprimido a otro fichero antes de poder ser usado.
El último y más bajo nivel de compresión es cuando el sistema de ficheros comprime los datos. En este caso, una aplicación que escribe en el fichero no conoce que el fichero esta siendo comprimido. Hay dos técnicas de compresión básicas usadas por los sistemas de ficheros. La más intuitiva es usar las mismas técnicas de compresión que se usan sobre ficheros y se aplican a las unidades de datos de los ficheros. La segunda técnica es no asignar una unidad de datos física si va a estar llena de ceros. Los ficheros que saltan unidades de datos llenas con ceros son llamados “sparse files”, y un ejemplo puede verse en la figura 8.12. hay muchas maneras de implementar esto, por ejemplo, en el Unix File System (UFS), se escribe un 0 a cada campo que usualmente almacena la dirección de un bloque. Un fichero no puede tener asignado el bloque 0, por lo que el sistema al leer el campo dirección sabe que ese bloque esta lleno de ceros.
Un fichero almacenado en formato “sparse” donde las unidades de datos con ceros no se escriben.

Los ficheros comprimidos pueden presentar un reto para un investigador porque la herramienta de investigación debe soportar los algoritmos de compresión. Además, algunas formas de búsqueda de cadenas y recuperación de ficheros son inefectivas debido a que examinan los datos comprimidos sin saber que lo están.
Ficheros encriptados
El contenido de un fichero puede ser almacenado en una forma encriptada para protegerlo contra accesos no autorizados. La encriptación puede ser aplicada por una aplicación externa (por ejemplo PGP), por la misma aplicación que crea el fichero o por el SSOO cuando crea el fichero. Antes de que un fichero se escriba en disco, el SSOOencripta el fichero y guarda el texto cifrado en la unidad de datos. Datos como el nombre del fichero y el último tiempo de acceso, normalmente no son encriptados. La aplicación que escribió los datos no conoce que el fichero está encriptado en el disco.Otro método de encriptación de contenidos de fichero es encriptar un volumen entero (por ejemplo con PGP Disk, Macintosh encrypted disk images y Linux AES encrypted loopback images). En este caso, todos los datos del sistema de ficheros son encriptados y no solo el contenido. En general, el volumen que contiene el SSOO no es encriptado completamente.
Los datos encriptados pueden presentar un reto a un investigador ya que la mayoría de los ficheros son inaccesibles si no se conoce la clave de encriptacióno password. En el peor de los casos, si no se conoce la técnica de encriptación. Algunas herramientas existen para probar cada combinación posible de claves o passwords, llamados ataques de fuerza bruta, pero estos no son útiles si no se conoce el algoritmo. En cualquier caso, si solo se encriptaron algunos ficheros y directorios en lugar del volumen entero, pueden encontrarse copias de los datos desencriptados en los ficheros temporales o en el espacio no asignado, ya que probablemente el fichero fue borrado.
Técnicas de análisis
Vamos a ver como se analizan datos en la categoría meta-datos. Usaremos los metadatos para ver el contenido de los ficheros, buscar valores y localizar ficheros borrados.
Búsqueda de Metadatos
En muchos casos, analizamos los metadatos porque encontramos el nombre de un fichero que apunta a una estructura de metadatos específica y queremos aprender más sobre el fichero. Por lo tanto, necesitamos ubicar los metadatos y procesar su estructura de datos. Por ejemplo, si buscamos a través de los contenidos de un directorio y encontramos un fichero llamado “secretos.txt”, podemos querer saber su contenido y cuando fue creado. La mayoría de las herramientas automáticamente realizan esta búsqueda cuando se listan los nombres de fichero en un directorio y permiten ordenar la salida basándose en los valores de meta-datos.
Los procedimientos exactos para esta técnica dependen del sistema de ficheros porque los meta-datos podrían estar en varios lugares del sistema de ficheros.
Después de buscar los meta-datos de un fichero, podemos ver los contenidos del fichero leyendo las unidades de datos asignadas al fichero. Haremos esto cuando estemos buscando evidencias en el contenido de un fichero.
Este proceso ocurre en las categorías de meta-datos y contenido. Sumaos la técnica de búsqueda de meta-datos para encontrar las unidades de datos asignadas al fichero y luego usar la técnica de visionado de contenido para encontrar el contenido actual. Podemos verlo enla figura 8.14 donde las unidades de datos asignadas a las entradas de meta-datos 1 y 2 son mostradas. Muchas herramientas gráficas combinan este proceso con el listado de nombres de ficheros. Cuando se selecciona un fichero, la herramienta busca las unidades de datos que se listan en los meta-datos.
Combinamos la información de las entradas de metadatos y las unidades de datos para ver el contenido de un fichero.
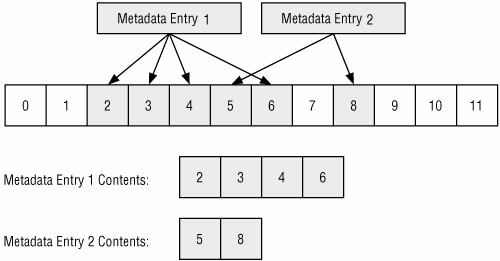
Durante este proceso, necesitamos mantener en mente el slack space porque el fichero puede no estar usando completamente el final de la unidad de datos.
Calcularemos cuanto espacio se está usando al final dividiendo el tamaño del fichero entre el tamaño de una unidad de datos.
Búsqueda lógica de ficheros
La técnica anterior asumió que tenemos los meta-datos para encontrar el contenido de un fichero y poder ver su contenido. Muchas veces, este no es el caso y tendremos que buscar un fichero basándonos en su contenido. Por ejemplo, si queremos todos los ficheros con la palabra “virus” dentro de él. Esto es lo que llamamos una búsqueda lógica de ficheros. Esta búsqueda usa las mismas técnicas que vimos para el visionado de ficheros, salvo que ahora buscamos datos con un valor específico en vez de visionarlos.
Este proceso puede sonar muy similar a la búsqueda lógica en el sistema de ficheros. Lo es, excepto que ahora buscamos las unidades de datos en el orden que fueron usadas por ficheros y no por su ordenación en el volumen. Podemos verlo en la figura 8.15 donde tenemos dos entradas de meta-datos y las unidades de datos que tienen asignadas. En este caso, buscamos las unidades de datos 2, 3, 4 y 6 como un conjunto (un fichero). El beneficio de esta búsqueda sobre la búsqueda lógica del sistema de ficheros esque los valores que las unidades de datos o sectores fragmentados serán encontrados. Por ejemplo, en este caso estamos buscando el término “forense” comenzando desde la unidad de datos 4 y terminando en la 6. No lo encontraríamos en la búsqueda lógica delsistema de ficheros porque no está contenido en unidades de datos consecutivas. Una variación de esta búsqueda es buscar un fichero con un valor hash específico MD5 o SHA-1.
Una búsqueda lógica en las unidades de datos asignadas a una entrada de metadatos**.**

Teniendo en cuenta que solo las unidades de datos asignadas tienen dirección lógica de fichero, deberíamos realizar una búsqueda lógica de volumen de las unidades de datos no asignadas para el mismo valor. Por ejemplo, una búsqueda lógica de fichero con la configuración de la figura anterior, no se hubiera buscado en las unidades de datos 0 y 1, de modo que deberíamos hacer una segunda búsqueda que incluya 0, 1, 7, 9, 10, 11 y así sucesivamente.
Análisis de Meta-datos No Asignados
Si estamos buscando contenido borrado, no deberíamos limitarnos solo a los nombres de ficheros borrados que son mostrados en un listado de directorio. Veremos algunos ejemplos en la Categoría de Nombre de Ficheros, pero es posible que se reuse un nombre de fichero antes que lo sea la estructura de meta-datos. Por tanto, nuestra evidencia podría estar en una entrada de meta-datos no asignada y no podríamos verla porque ya no tiene un nombre.
Búsqueda y Ordenación de Atributos de Meta-Datos
Es bastante común buscarficheros basándose en uno de sus valores de meta-datos.
Por ejemplo, podría ser que encontramos una alerta en el log de un IDS (Intrusion Detection System) y queremos encontrar todos los ficheros que fueron creados dos minutos después de que se iniciara la alarma. O puede ser que estemos investigando un usuarioy queramos encontrar todos los ficheros que en los que escribió en un determinado momento.
Los tiempos de fichero pueden cambiarse fácilmente en algunos sistemas, pero también pueden proporcionarnos muchas pistas. Por ejemplo, si tenemos una hipótesis de que un atacante ganó acceso a una computadora a las 8:13 p.m. e instaló herramientas de ataque, podemos probar la hipótesis buscando todos los ficheros creados entre las 8:13 p.m. y las 8:23 p.m. Si no encontramos ningún fichero de interés en este intervalo de tiempo, pero encontramos herramientas de ataque que fueron creadas en un tiempo diferente, podemos sospechar que los tiempos han sido manipulados, que nuestra hipótesis es incorrecta o ambas cosas.
Los datos temporales pueden también ser usados cuando nos encontramos con una computadora que conocemos un poco. Los datos temporales muestran qué ficheros fueron recientemente accedidos y creados. Esa información puede darnos sugerencias sobre como se usó una computadora.
Algunas herramientas crean líneas de tiempo de la actividad del fichero. En muchas líneas de tiempo, cada fichero tiene tantas entradas en la línea de tiempo como valores temporales. Por ejemplo, si tiene el último acceso, la última escritura y la última modificación, tendremos tres entradas en la línea de tiempo.
En TSK, la herramientamactimese usa para hacer lineas de tiempo. Un ejemplo de la salida de mactime para el directorioC:\Windowspodría ser:
Wed Aug 11 2004 19:31:58 34528 .a. /system32/ntio804.sys
35392 .a. /system32/ntio412.sys
[REMOVED]
Wed Aug 11 2004 19:33:27 2048 mac /bootstat.dat
1024 mac /system32/config/default.LOG
1024 mac /system32/config/software.LOG
Wed Aug 11 2004 19:33:28 262144 ma. /system32/config/SECURITY
262144 ma. /system32/config/default
En la salida anterior, podemos ver la actividad del fichero en cada segundo. La primera columna tiene la marca de fecha, la segunda es el tamaño del fichero, y la tercera muestra si esta entrada contiene tiempo de modificación (m-time), acceso al contenido (a-time), o cambio en los meta-datos (c-time). La última columna muestra el nombre del fichero. Hay mucha más información que no se muestra ya que esto es solo un ejemplo.
Nótese que se debe entender como un sistema de ficheros almacena sus marcas de tiempo antes de intentar correlacionar tiempos de ficheros y entradas de log de varias computadoras. Algunas marcas de tiempo se almacenan en UTC, que significa que se necesita saber el desplazamiento de la zona de tiempo donde se ubicaba la computadora para determinar el valor actual de tiempo. Por ejemplo, si alguien accede a un fichero a las 2:00 p.m. en Boston, el SSOO grabará que accedí a las 7:00 p.m. UTC, ya que Boston se encuentra cincohoras detrás de la UTC. Cuando un investigador analiza el fichero, necesita convertir las 7:00 p.m. a las 2:00 p.m., hora de Boston (lugar donde ocurrieron los hechos) o a su hora local (si el análisis no se realiza en Boston). Otros sistemas de ficherosalmacenan el tiempo con respecto a la zona de tiempo local, y almacenaría 2:00 p.m. en el ejemplo previo.
Podemos además querer buscar ficheros para los cuales un determinado usuario ha tenido acceso de escritura. Esto muestra qué ficheros podría haber creado un usuario, si asumimos que el SSOO impone permisos y el sospechoso no tenía permisos de administrador. También podemos buscar por el ID del propietario del fichero, si existe. Este método se usa cuando investigamos un usuario específico.
Si previamente hemos realizado una búsqueda lógica del sistema de ficheros y encontramos datos interesantes en una de las unidades de datos, podemos querer buscar las entradas de meta-datos para esa dirección de unidad de datos. Esto puede mostrar qué ficheros tienen asignada la unidad de datos y a continuación podemos encontrar las otras unidades de datos que son parte del mismo fichero. Un ejemplo de esto podemos encontrarlo en la figura 8.16, donde tenemos una evidencia en la unidad de datos 34. Buscamos los meta-datos y encontramos que la estructura de meta-datos 107 apunta a esa unidad de datos, a la vez que a la 33 y la 36. Si el SSOO no limpia los valores dirección cuando un fichero es borrado, este proceso puede identificar estructuras de meta-datos no asignadas.
Puede ser útil buscar entre las estructuras de meta-datos para encontrar una que tenga unidades de datos asignadas.
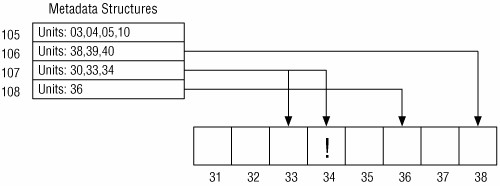
Orden de asignación de las estructuras de datos
Si necesitamos saber los tiempos relativos de asignación entre dos entradas, debemos ser capaces de comprender la estrategia de asignación del SSOO para determinarlo. Esto es muy dependiente de cada SSOO y bastante difícil. Las entradas de meta-datos son normalmente asignadas usando la estrategia de la primera disponible o la siguiente disponible.
Pruebas de consistencia
Una prueba de consistencia con los meta-datos puede revelar intentos de esconder datos o puede mostrarnos que la imagen del sistema deficheros tiene algunos errores internos que nos impedirán ver información precisa. Los únicos datos con los que podemos obtener conclusiones en una prueba de consistencia son con los datos esenciales, que incluyen las direcciones de unidad de datos, el tamaño y el estado de asignación de cada entrada de meta-datos.
Una prueba que puede realizarse consiste en examinar cada entrada asignada y verificar que las unidades de datos que tiene asignadas se encuentran en estado asignado. Esto puede verificar que elnúmero de unidades de datos asignadas es consistente con el tamaño del fichero. La mayoría de los sistemas de ficheros no asignan más unidades de datos de las necesarias.
Además podemos verificar que las entradas para los tipos especiales de ficheros notienen unidades de datos asignadas a ellos. Por ejemplo, algunos sistemas de ficheros tienen ficheros especiales llamados sockets que son usados para procesar comunicaciones con otro usuario y no pueden alojar unidades de datos.
Otra prueba de consistencia usa información de los datos de la categoría de nombre de fichero y verifica que cada entrada de directorio asignada tiene un nombre asignado que apunta a él.
Técnicas de limpieza
Los meta-datos pueden ser limpiados cuando un fichero es borrado para hacer más difícil recuperar ficheros. Los tiempos, tamaño y direcciones de unidades de datos pueden limpiarse con ceros o datos aleatorios. Un investigador puede detectar una limpieza encontrado una entrada llena de ceros u otros datos inválidos si comparamos con una entrada válida. Una herramienta de limpieza más inteligente llenaría los valores con datos válidos pero que no tuvieran correlación con el fichero original.
3.5.4.5 CATEGORÍA NOMBRE DE FICHERO
Esta categoría incluye los nombres de ficheros, que permiten al usuario referirse a un fichero por su nombre en vez de por su dirección de meta-datos. En esencia,esta categoría de datos incluye sólo el nombre de un archivo y su dirección de metadatos.Algunos sistemas de archivo también pueden incluir información de tipo del archivo o información temporal,pero eso no es estándar
Una parte importante del análisis de nombre de fichero es determinar donde se encuentra alojado el directorio raíz, ya que lo necesitamos para encontrar un fichero si nos dan la ruta completa. El directorio raíz es el directorio base del cual cuelgan todos los demás directorios. Por ejemplo, en Windows “C:\” es el directorio raíz de la unidad C:. Cada sistema de ficheros tiene supropia forma de definir la localización del directorio raíz.
Información General
En esta sección, vamos a ver los conceptos generales de la categoría de nombre de fichero. Esta categoría es relativamente simple y necesitamos ver solamente la recuperación de ficheros basada en el nombre de fichero.
Recuperación de ficheros basada en el Nombre del Fichero
Anteriormente vimos en la categoría de Meta-datos que los ficheros borrados pueden recuperarse usando sus meta-datos. Ahora usaremos el nombre del fichero borrado y sus correspondientes direcciones de meta-datos para recuperar el contenido del fichero usando recuperación basada en meta-datos. En otras palabras, la parte difícil se hace en la capa de meta-datos, y todo lo que tenemos que hacer en esta capa es identificar las entradas de meta-datos en las cuales enfocar nuestra atención.
Podemos verlo en la figura 8.17 conde tenemos dos nombres de ficheros y tres entradas de meta-datos. El fichero favorites.txt esta borrado, y su nombre apunta a una entrada de meta-datos no asignada. Podemos intentar recuperar el contenido de los meta-datos usando técnicas de recuperación basadas en meta-datos. Nótese que el contenido de la entrada de meta-datos 2 también puede ser recuperado, aunque no tenga un nombre.
Podemos recuperar ficheros basándonos en su nombre, pero aun así se usarán técnicas de meta-datos para la recuperación.

Para finalizar, si examinamos ficheros borrados desde la perspectiva de nombre de fichero, debemos tener en cuenta que los meta-datos y las unidades de datos podrían haber sido reasignadas a otro fichero. Además recordar que se necesita examinar las estructuras de meta-datos no asignadas para encontrar las que no tienen nombres apuntando hacia ellas.
Técnicas de Análisis
En esta sección veremos las técnicas de análisis que pueden realizarse con los datos de la categoría de nombre de fichero.
Listado de**nombre de fichero
El propósito de la categoría de nombre de fichero es asignar nombres a los ficheros. Por tanto, no debe sorprendernos que una de las técnicas de investigación más comunes sea listar los nombres de los ficheros y directorios. Haremos esto cuando busquemos evidencias basándonos en el nombre, la ruta o la extensión de un fichero. Después de que un fichero ha sido reconocido, podemos usar su dirección de metadatos para obtener más información. Variaciones en esta técnica ordenarán los ficheros basándose en sus extensiones de modo que los ficheros del mismo tipo son agrupados.
Muchos sistemas de ficheros no limpian el nombre del fichero de un fichero borrado, de modo que los nombres de ficheros borrados pueden ser mostrados en el listado. Sin embargo, en algunos casos, la dirección de meta-datos es borrada cuando un fichero es borrado, y puede que no seamos capaces de obtener más información.
El principio de esta técnica es buscar el directorio raíz del sistema de ficheros. Este proceso esnormalmente el mismo que el que se vio para la técnica de visionado lógico de ficheros en la categoría meta-datos. El diseño del directorio raíz se almacena en una entrada de meta-datos, y necesitamos encontrar la entrada y las unidades de datos que el directorio tiene asignadas.
Después de localizar los contenidos del directorio, los procesaremos y obtendremos una lista de ficheros y sus correspondientes direcciones de meta-datos. Si un usuario quiere ver el contenido de un fichero de los que se lista, puede usar la técnica del visionado lógico de ficheros usando la dirección de meta-datos. Si un usuario quiere listar los contenidos de un directorio diferente, deberá cargar y procesar los contenidos del directorio. En otro caso, este proceso se basa en elvisionado lógico de ficheros.
La mayoría de las herramientas de análisis ofrecen esta técnica, y muchas combinan los datos de la categoría de nombre de fichero con los datos de la categoría meta-datos, de modo que podamos ver, por ejemplo, las fechas y horas asociadas con el nombre delfichero en una vista. La figura 8.20 muestra un ejemplo de este proceso de análisis donde procesamos la unidad de datos 401 y encontramos dos nombres. Nosotros estamos interesados en el fichero “favorites.txt” y nos percatamos de que su meta-datos es la entrada 3. Nuestro sistema de ficheros almacena que la estructura de meta-datos 3 apunta a la unidad de datos 200, de modo que procesaremos los datos relevantes de la unidad de datos y obtendremos el tamaño y las direcciones del contenido del fichero.
Rela**ción entre nombres de fichero y metadatos.**
Búsqueda de nombre de fichero
El listado de nombres de ficheros trabaja bien si sabemos el fichero que estamos buscando, pero ese no es siempre el caso. Si no sabemos el nombre completo del fichero, podemos buscar las partes que conocemos. Por ejemplo, podemos saber la extensión, o podemos saber el nombre del fichero, pero no la ruta completa. Una búsqueda mostrará una serie de ficheros que cumplen con un patrón de búsqueda. En la figura 8.20, si hiciéramos una búsqueda por un fichero con extensión “.txt”, la herramienta examinaría cadaentrada y devolvería “badstuff.txt” y “favorites.txt”. Nótese que buscando por la extensión no necesariamente se devuelven ficheros de un cierto tipo ya que la extensión puede haber sido cambiada a propósito para esconder el fichero. Las técnicas de análisis a nivel de aplicación que dependen del nombre de la estructura del fichero pueden usarse para encontrar todos los ficheros de un cierto tipo.
El proceso requerido para buscar un nombre es igual que el que vimos para el listado de nombres de fichero:cargar y procesar los contenidos de un directorio. Comparamos cada entrada del directorio con el patrón objetivo. Cuando encontramos un directorio, debemos buscar dentro de él si hacemos una búsqueda recursiva.
Otra búsqueda de esta categoría es buscar elnombre del fichero que tiene asignada una cierta entrada de meta-datos. Esto es necesario cuando encontramos evidencias en una unidad de datos y luego buscamos la estructura de meta-datos que tiene asociada.
Pruebas de consistencia
Las pruebas de consistencia para esta categoría verifican que todos los nombres asignados apuntan a una estructura de metadatos con estado asignado. Esto es válido para algunos sistemas de ficheros que tienen múltiples nombres de ficheros para el mismo fichero, y muchos de ellos implementan esta funcionalidad teniendo más de una entrada de nombre de fichero con la misma dirección de meta-datos.
Técnicas de borrado seguro
Una herramienta de borrado seguro en esta categoría limpia los nombres y direcciones de meta-datos de la estructura. Una técnica de borrado seguro debe escribir sobre los valores en la estructura de nombre de fichero, de modo que un análisis mostrará que existió una entrada pero los datos ya no son válidos. Por ejemplo, el nombre de fichero “setplog.txt” podría ser reemplazado por “abcdefgh.123”. Con algunos SSOO, esto es difícil, ya que el SSOO ubicará el nuevo nombre al final de una lista, usando una estrategia del siguiente disponible.
Otra técnica de limpieza de nombres de fichero esreorganizar la lista de nombres de modo que uno de los nombres de fichero existentes sobrescribe el nombre de fichero borrado. Esto es mucho más complejo que el primer método y mucho más efectivo que una técnica de ocultamiento porque el investigador nunca sabrá que hay algo fuera de lo normal en ese directorio.
3.5.4.6 CATEGORÍA APLICACIÓN
Algunos sistemas de ficheros contienen datos que pertenecen a la categoría aplicación. Estos datos no son esenciales para el sistema de ficheros, y normalmente existen como datos especiales del sistema de ficheros en lugar de un fichero normal ya que es más eficiente. Esta sección cubre una de las características más comunes de la categoría de aplicación, llamada “journaling” o bitácora.
Técnicamente, cualquier fichero que un SSOO o aplicación crea, podría ser designado como una característica en un sistema de ficheros. Por ejemplo, Acme Software podría decidir que sus SSOO deberían ser más rápidos si un área del sistema de ficheros es reservada como un libro paraanotar direcciones. En lugar de salvar nombres y direcciones en un fichero, deberían salvarse en una sección especial del volumen. Esto puede producir una mejora en el rendimiento, pero no es esencial para el sistema de ficheros.
Journals del sistema de f**icheros**
Como cualquier usuario de computadoras sabe, no es inusual para una computadora pararse y quedarse colgada. Si el SSOO estaba escribiendo datos en el disco o si estaba esperando para escribir algunos datos al disco cuando la computadora se colgó, es probable que el sistema de ficheros esté en un estado inconsistente. Podría haber una estructura de meta-datos con unidades de datos asignadas, pero sin punteros entre ellos ni nombre de fichero apuntando a la estructura de meta-datos.
Para encontrar las inconsistencias, un SSOO arranca un programa que escanea el sistema de ficheros y busca punteros perdidos y otros signos de corrupción. Esto puede tomar un buen rato para sistemas de ficheros grandes. Para hacer el trabajo del programa de escaneo más fácil, algunos sistemas de ficheros implementan un journal. Antes de que ninguna estructura de meta-datos cambie en el sistema de ficheros, se hace una entrada en el journal que describe el cambio que ocurrirá. Después de que se hagan los cambios, se incluye otra entrada en el journal para indicar que los cambios se han producido con éxito. Si el sistema se cuelga, el programa de escaneo lee el journal y localiza las entradas que no fueron completadas. Más tarde el programa completa los cambios o los deshace a su estado original.
Muchos sistemas de ficheros ahora soportan journaling ya que ahorran tiempo son sistemas grandes. El journal está en la categoría de aplicación porque no es necesario para el sistema operativo para funcionar. Existe para hacer más rápidas las pruebas de consistencia.
Los journals de sistemas de ficheros pueden sernos útiles en investigaciones, aunque hasta hoy no son completamente utilizados. Un journal muestra qué eventos del sistema de ficheros han ocurrido recientemente, y esto podría ayudar con la reconstrucción de eventos de un incidente reciente. La mayoría de las herramientas forenses no procesan los contenidos del journal de un sistema de ficheros.
3.5.4.7TÉCNICASDEBÚSQUEDAANIVELDEAPLICACIÓN
En esta sección se discutirán las distintas técnicas que nos permitirán recuperar ficheros borrados y organizar ficheros no borrados para su análisis. Estas técnicas son independientes del sistema de ficheros.
Ambas de esas técnicas se apoyan en el hechode que muchos ficheros tienen estructura para ellos, incluyendo un valor “firma” que es único para ese tipo de fichero. La firma puede usarse para determinar el tipo de un fichero desconocido.
Recuperación de ficheros basada en aplicación (Data Carving)
Este es un proceso donde una porción de datos es examinada para buscar firmas que correspondan al inicio o final de tipos de ficheros conocidos. El resultado de este proceso de análisis es una colección de ficheros que contienen una de las firmas. Estose realiza normalmente en el espacio no asignado de un sistema de ficheros y permite al investigador recuperar que no tienen estructura de meta-datos apuntando a ellos. Por ejemplo, una imagen JPEG tiene unos valores estándar para la cabecera y la cola. Uninvestigador puede querer recuperar imágenes borradas, por lo que debería usar una herramienta que busque las cabeceras JPEG en el espacio no asignado y que extraiga el contenido que comprende desde la cabecera hasta la cola del fichero encontrado.
Una herramienta de ejemplo que realiza esto es FOREMOST [22] que ha sido desarrollada por los agentes especiales Kris Kendall y Jesse Kornblum de la Oficina de Investigaciones especiales de las fuerzas aéreas de los Estados Unidos. Foremost analiza un sistema de ficheros en bruto o una imagen de disco basada en los contenidos de un fichero de configuración, que tiene una entrada para cada firma. La firma contiene el valor de cabecera conocido, el tamaño máximo del fichero, la extensión típica del fichero, si existe sensibilidad a las mayúsculas y minúsculas y un valor opcional de cola. Un ejemplo puede verse aquí para un JPEG:
jpg y 200000 \xff\xd8 \xff\xd9
Esto muestra que la extensión típica es “jpg”, que la cabecera y la cola son sensibles a las mayúsculas y minúsculas, que la cabecera es 0xffd8 (valor hexadecimal) y que la cola es 0xffd9. El tamaño máximo del fichero es 200.000 bytes Si no se encuentra la cabecera tras leer todos los datos, se parará para ese fichero. En la figura 8.21 podemos ver un conjunto de datos de ejemplo donde la cabecera JPEG es encontrada en los dos primeros bytes del sector 902 y el valor cola es encontrado en el medio del sector 905. Los contenidos de los sectores 902, 903, 904 y el inicio del sector 905 serían extraídos como una imagen JPEG.
Bloques de datos en bruto en los que encontramos una imagen JPEG mediante su cabecera y su cola

Una herramienta similar es LAZARUS (disponible en The Coroner's Toolkit [31] en realizada por Dan Farmer, la cual examina cada sector de una imagen de datos en bruto y ejecuta el comando file sobre ella. Se crean grupos de sectores consecutivos que tienenel mismo tipo. El resultado final es una lista con una entrada para cada sector y su tipo. Esto es básicamente un método de ordenación de las unidades de datos usando sus contenidos. Este es un concepto interesante, pero la implementación es en Perl y puede ser lenta.
Ordenación de tipos de fichero
Los tipos de fichero pueden usarse para organizar los ficheros en un sistema de ficheros. Si la investigación esta buscando un tipo específico de datos, un investigador puede ordenar los ficheros basándose ensu estructura. Una técnica de ejemplo podría ser ejecutar el comando file sobre cada fichero y agrupar tipos similares de ficheros. Esto agruparía todas las imágenes y todos los ejecutables en grupos diferentes, por ejemplo. Muchas herramientas forenses tienen esta característica, pero no siempre esta claro si la ordenación está basada en la extensión o en la firma del fichero.
SISTEMAS DE FICHEROS ESPECÍFICOS
Pare tener una referencia, la tabla 8.1 contiene los nombres de las estructuras de datos en cada categoría para los distintos sistemas de ficheros.
| **Las estructuras de datos en cada categoría de datos | |
|---|---|
| Sistema de Contenido Metadatos Nombre ficherosfichero | de Applicación |
| Ext2,Superbloque, Bloques,Inodos, Mapa de Entradas | de Journal |
| FAT Sector de Clusters, Entradas de Entradas arranque, FAT directorio, FAT directorio FSINFO | de N/A |
| **Las estructuras de datos en cada categoría de datos | |
| Sistemade Contenido MetadatosNombrede Applicación ficherosfichero | |
| NTFS $Boot,Clusters,$MFT,$FILE_NAME, Cuotade | |
| UFSSuperbloque, Bloques,Inodos, mapa de Entradasde N/A grupo,fragmentos, bitsdeinodos, directorio descriptormapade atributos |
Hay otros sistemas de ficheros que no se mencionan, pero que podemos encontrarnos. HFS+ es el sistema de ficheros por defecto de las computadoras Apple. Apple ha publicado las estructuras de datos y detalles del sistema de ficheros. ReiserFS es uno de lossistemas de ficheros Linux y es el que toman por defecto algunas distribuciones como SUSE. El Journaled File System (JFS) para Linux es de IBM, y es otro sistema de ficheros que se usa en los sistemas Linux. Nótese que es diferente del sistema de ficherosJFS que IBM desarrolló para sus sistemas AIX.
3.5.4.9 RESÚMEN
El análisis de un sistema de ficheros se usa para generar la mayoría de las evidencias en las investigaciones digitales actuales. Hemos visto las categorías de datos en un sistema de ficheros, de forma que tengamos una buena base a la hora de investigar unsistema de ficheros. Hemos visto también técnicas de análisis para cada categoría de datos desde un punto de vista académico. La tabla 8.2 muestra un resumen de las técnicas de análisis que pueden usarse basadas en los tipos de datos que estamos buscando.
Los métodos y lugares de búsqueda, dependiendo del tipo de evidencia que se busque
| Necesidades del análisisCategoría de datosTécnica de búsqueda |
|---|
| Un fichero basado en su Nombre de fichero Búsqueda de nombre de fichero o nombre, extensión o listado de contenidos de |
| Un fichero asignado o no, Nombre de fichero y Búsqueda de atributos de metabasado en sus valores de meta-datos datos tiempo |
| Un fichero asignado basado Nombrede Búsqueda lógica de sistema de |
| Un fichero asignado basado Nombre de fichero Búsqueda lógica de sistema de en su valor HASH (usando meta-datos y ficheros con valores hash |
| Un fichero asignado o una Nombre de fichero Búsqueda lógica de sistema de unidad de datos no asignada (usando meta-datos y ficheros con recuperación basada basados en un valor de su contenido) en meta-datos y búsqueda lógica |
| Un fichero no asignado Aplicación y Recuperación basada en basado en su tipo de contenido aplicación de unidades de datos |
| Datos no asignados basados Contenido Búsqueda lógica de sistema de en su contenido(y no su tipo ficheros de aplicación) |
3.5.5 Reconstrucción
Una reconstrucción investigativa nos ayuda a obtener una imagen más completa del delito: que ha pasado, quien causó los eventos, cuando, donde, como y porqué. La evidencia digital es una fuente de información rica y a menudo inexplorada. Puede establecer acciones, posiciones, orígenes, asociaciones, funciones, secuencias y más datos necesarios para una investigación. Los ficheros Log son una fuente particularmente rica de fuente de información sobre conductas, ya que graba muchas acciones. Interpretando correctamente la información de varios ficheros log, es a menudo posible determinar lo que hizo un individuocon un alto grado de detalle.
Las piezas individuales de datos digitales pueden no ser útiles por sí mismas, pero pueden revelar patrones cuando las combinamos. Si una víctima lee su correo a una hora específica o frecuenta una zona particular de internet, una ruptura en este patrón puede ser el indicativo de un evento inusual. Un delincuente puede solo trabajar los fines de semana, en un cierto lugar, o de una única manera. Teniendo esto en cuenta podemos decir que existen tres formas de reconstrucción que deberían realizarse cuando se analizan evidencias para desarrollar una imagen más clara de un delito y ver discrepancias o brechas.
Análisis Temporal (cuando): ayuda a identificar secuencias y patrones de tiempo en los eventos.
Análisis Relacional (quien, que y donde): los componentes de un delito, su posicion e interacción.
Análisis Funcional (como): qué fue posible e imposible.
3.5.5.1 Análisis Temporal
Cuando se investiga un delito, es normalmente deseable conocer la fecha, la hora y la secuencia de eventos. Afortunadamente, además de almacenar, recuperar, manipular y transmitir datos, los ordenadores mantienen muchos registros de tiempo. Por ejemplo, la mayoría de los sistemas operativos están al tanto de la creación, modificación y acceso de ficheros y directorios. Estos “sellos de tiempo” pueden ser muy útiles a la hora de determinar qué ocurrió en la computadora. En una investigación de robo de propiedad intelectual, los sellos de tiempo de los ficheros pueden mostrarcuanto tardó el intruso en localizar la información deseada en un sistema y a qué ficheros accedió. Una mínima cantidad de búsqueda (ficheros accedidos por el intruso), indica que conocía bien el sistema atacado y una gran búsqueda indica menos conocimiento del sistema. En una investigación de pornografía infantil, el sospechoso declara que su esposa puso pornografía en su ordenador personal sin su conocimiento durante su amarga separación para que repercutiera negativamente en la batalla por la custodia de sus hijos. Sin embargo, los sellos de tiempo de los ficheros indican que fueron ubicados en el sistema mientras su enemistada esposa estaba fuera del país visitando a su familia.
También, el ordenador del sospechoso contenía restos de e-mails y otras actividades online, indicando que había usado la computadora en ese tiempo.
Además de los sellos de tiempo, algunas aplicaciones incrustan información de fecha-tiempo dentro de los ficheros o logs creados, así como bases de datos, que pueden mostrar por ejemplo, las páginas Web visitadas.
Cuando se investiga un delito que implica ordenadores, es importante poner especial atención a la fecha/hora en que se cometió, a cualquier discrepancia entre la hora actual y la hora del sistema, la zona horaria del reloj de la computadora y los sellos de tiempo en objetos digitales.
El simple acto de creación de una linea de tiempo de cuando los ficheros implicados fueron creados, modificados y accedidos puede resultar en una sorprendente cantidad de información. Creando una línea de tiempo de eventos puede ayudar al investigador a identificar patrones y brechas, arrojando luz sobre un delito y llevándonos a otras fuentes de evidencia. Por ejemplo, la siguiente figura muestra una linea de tiempo de las actividades de unamujer perdida en los días anteriores a su desaparición como se reconstruye de su computadora. La secuencia cronológica de eventos ayuda al investigador a determinar que la víctima había viajado a Virginia a tener un encuentro masoquista con un hombre queconoció online. Cuando el investigador buscó la casa del hombre, encontraron el cuerpo de la mujer.
| Linea de tiempo de actividades sobre la computadora de la víctima, mostrando correspondencia de e-mail, sesiones de chat online, ficheros borrados, búsqueda de mapas en la Web y planos online para viajar. | |
|---|---|
| DATE | ACTIVITY |
| Dia 1 | Webs sadomasoquistas (BDSM) visitadas |
| Dia 2 | Correspondencia de Hotmail de naturaleza BDSM con origen desconocido, IP de virginia. Alrededor de la misma hora se ingresa en Hotmail para revisar el correo. Se visitan más páginas BDSM. |
| Dia 3 | Logs de conversaciones de sesiones de chat online muestran una conversación de naturaleza sexual/BDSM con origen desconocido e IP de Virginia. |
| Dia 4 | Direcciones obtenidas desde MapQuest, en dirección a virginia. |
| Dia 4 | Fichero borrado |
| Dia 4 | No hay actividad despues de las 8 P.M. |
Representando la información temporal en deferentes formas se pueden extraer patrones. Por ejemplo, la siguiente figura muestra un histograma de sellos de tiempo de una computadora usada por los trabajadores del turno de noche de una compañía. Un empleadoes sospechoso de ver material obsceno y posiblemente ilegal durante su turno desde la media noche hasta las 8 A.M., pero las marcas de tiempo de los ficheros muestran que la actividad se realizó entre las 4 P.M. y la media noche, implicando así a su compañero.
Histograma de las marcas de tiempo (creados y modificados) mostrando una brecha entre los turnos sopechosos (las fechas están en inglés: Mes/Dia/Año)
Las brechas en la figura anterior sugieren que la computadora no fue usada durante el turno delsospechoso, pero es sabido que el empleado tuvo que hacer uso de los recursos de red para su trabajo (web, email), lo que indica que el sospechoso cambiaba regularmente el reloj del sistema al inicio de su turno a 8 horas antes. Resulta interesante que enuna de esas veces cambió accidentalmente el mes además de la hora, por lo que se produjo actividad que data del mes de Mayo, despues de 1600 horas. Esto apoya la hipótesis de que cambió la hora durante sus turnos. Además, se realizaba una copia de seguridad por la central todas las noches a las 2 A.M., que aparecían en el Windows NT Application Event Log como 8 horas antes, apoyando de nuevo la teoría de que el reloj había sido alterado.
Otra aproximación al análisis de la información de las marcas de tiempo es usando una tabla para acentuar patrones de cuando ocurrió un evento. La siguiente tabla muestra los e-mails enviados por el jefe de un grupo criminal durante muchos meses a otros miembros del grupo. Las comunicaciones sobre un plan criminal comenzaron a mediados de Junio, cesando a comienzos de Julio y retomándolas como fecha tope el 11 de Septiembre.
| Tabla que muestra los mensjaes de e-mail enviados por un sospechoso durante muchos meses a otros miembros de un grupo criminal. | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Direcciones de email | Dom, | Vie, | Dom, | Mie, | Sab, | Dom, | Jue, | Vie, | Lun, | Vie, | Mie, | Jue, | Jue, | Dom, | Mie, |
| Miembro1 | Xx | x | x | xxx | xx | X | |||||||||
| Miembro2 | Xx | x | x | x | x | x | x | x | x | x | |||||
| Miembro3 | Xx | x | x | x | x | X | xxx | x | x | x |
3.5.5.2 Análisis Relacional
En un esfuerzo para identificar relaciones entre sospechosos, la victima y la escena del crimen, puede ser útil crear un grafo con nodos que representan lugares en los que se ha estado o acciones que se han realizado, como IPs, e-mails, transacciones financieras, números de teléfono marcados, etc., y determinar si hay conexiones destacables entre esos nodos. Por ejemplo, en una investigación de fraude a gran escala, representando transferencias de fondos dibujando linas entre individuos y organizaciones sepuede revelar la mayor parte de la actividad en el fraude. Igualmente, trazando los mensajes de e-mail enviados y recibidos por un sospechoso podría ayudar a desvelar a supuestos cómplices por el gran número de mensajes intercambiados.
Es posible que contanta información parezca que nada esta conectado. Los investigadores deben decidir cuanto peso asignar a las relaciones que encuentren. Estas reconstrucciones dan mejores resultados en diagramas con pocas entidades. A medida que se incrementan las entidades y relaciones se incrementa la dificultad de identificar las conexiones importantes. Para facilitar esta tarea existen herramientas que ofrecen la posibilidad de realizar diagramas y asignar pesos a cada conexión. Además se están desarrollando otras herramientas que permiten trabajar con muchas entidades usando algoritmos sofisticados.
3.5.5.3 Análisis Funcional
Cuando se reconstruye un delito, a menudo es útil considerar qué condiciones fueron necesarias para hacer que ciertos aspectos del delitofueran posibles. Por ejemplo, a menudo es útil testear el hardware original para asegurarnos de que el sistema fue capaz de realizar algunas acciones básicas, como chequear la capacidad de una unidad de disquetes para leer/escribir si tenemos un disquetecon evidencias.
En una investigación hay varios propósitos para evaluar como funcionaba un sistema computacional:
Para determinar si el individuo o la computadora tenían capacidad para cometer el delito.
Para ganar un mejor entendimiento de una parte de la evidencia digital o del delito en general.
Para probar que la evidencia digital fue manipulada indebidamente.
Para comprender los motivos e intenciones del agresor. Por ejemplo, si fue algo accidental o premeditado.
Para determinar el funcionamiento del sistema durante el lapso de tiempo pertinente.
Debemos tener en mente que el propósito de la reconstrucción funcional es considerar todas las posibles explicaciones para un determinado conjunto de circunstancias, y no simplemente responder a la cuestión que se plantea.
Puede ser necesario determinar como un programa o computador estaba configurado para ganar un mejor entendimiento de un delito o una parte de una evidencia digital. Por ejemplo, si se requiere un password para acceder a cierta computadora o programa, este detalle funcional debería ser anotado. Conociendo que un cliente de e-mail estaba configurado para chequear automáticamente el correo en busca de mensajes nuevos cada 15 minutos, puede ayudar a los investigadores a diferenciar actoshumanos de actos automáticos.
3.5.6 Publicación de conclusiones
La última fase de un análisis de evidencias digitales es integrar todo el conocimiento y conclusiones en un informe final que de a conocer los descubrimientos a otros y que el examinador puede tener que presentar en un juicio. La escritura de un informe esuna de las fases más importantes del proceso, ya que es la única presentación visual que otros tendrán sobre el proceso entero. A menos que los descubrimientos sean comunicados claramente en el informe, es improbable que otros aprecien su significancia. Un buen informe que describe claramente los descubrimientos del examinador puede convencer a la oposición a llegar a un acuerdo en un juicio, mientras que un informe pobre puede animar a la oposición para ir a juicio. Las suposiciones y la falta de fundamentos resultan en un informe débil. Por tanto, es importante construir argumentos sólidos suministrando todas las evidencias encontradas y demostrando que la explicación proporcionada es la más razonable.
Mientras sea posible, respaldar las suposiciones conmúltiples fuentes independientes de evidencia e incluyendo todas las pruebas relevantes junto con el informe ya que puede ser necesario en un juicio hacer referencia a las mismas cuando se explican los descubrimientos en el informe. Establecer claramentecomo y donde se encontró toda la evidencia para ayudar a los que tomarán las decisiones a interpretar el informe y permitir a otros examinadores competentes a verificar resultados. Presentando escenarios alternativos y demostrando porqué son menos razonables y menos consistentes con respecto a la evidencia puede ayudar a reforzar las conclusiones clave. Explicando porqué otras explicaciones son improbables o imposibles demuestra que el método científico fúe aplicado, es decir, que se hizo un esfuerzo para desmentir la conclusión alcanzada por el examinador, pero que esta resistió un escrutinio crítico. Si la evidencia digital fue alterada después de recopilarla, es crucial mencionar esto en el informe, explicando la causa de las alteraciones y sopesando su impacto en el caso (por ejemplo, insignificante, servero).
A continuación se muestra una estructura simple para un informe:
Introducción: Número de caso, quien requirió el informe y qué se buscaba, quien escribió el informe, cuando y que se encontró.
Resumen de la evidencia: resumir qué evidencias se examinaron y cuando, valores MD5, cuando y donde se obtuvo la evidencia, de quién y su condición (anotar signos de daño o sabotaje)
Resumen del análisis: resumir las herramientas usadas para realizar el análisis, cómo se recuperaron los datos importantes (por ej: si se desencriptaron, o se recuperaron ficheros borrados) y como se descartaron ficheros irrelevantes.
Análisis del sistema de ficheros: inventario de ficheros importantes, directorios y datos recuperados que son relevantes para la investigación con características importantes como nombres de ruta, marcas de tiempo, valores MD5, y localización física de los sectores en el disco. Nótese cualquier ausencia inusual de datos.
Análisis/Reconstrucción: describir e interpretar el proceso de análisis temporal, relacional y funcional.
Conclusiones: el resumen de conclusiones debería seguir a las secciones previas en el informe y debería hacer referencia a la evidencia hallada y a la imagen reconstruida a partir de ellas.
Glosario de Términos: explicaciones de términos técnicos usados en el informe
Apéndice de soporte: la evidencia digital usada para alcanzar las conclusiones, claramente numerada para su referencia.
Además de presentar lo hechos en un caso, los investigadores digitales generalmente interpretan la evidencia digital en el informe final. La interpretación implica opinión, y cada opinión suministrada por un investigador tiene una base estadística. Por tanto en un informe el investigador debe indicar claramente el nivel de certeza que tiene cada conclusión y cada parte de la evidencia para ayudar en un juicio a darles un peso a cada una. La Escala de Certeza de Casey(C-Scale, Casey Certainly Scale) proporciona un método para transmitir certeza cuando nos refereimos a una evidencia digital en un contexto dado y cualificar las conclusiones apropiadamente.
| NIVEL DE CERTEZA | INDICADORES/ DESCRIPCIÓN | CALIFICACIÓN | EJEMPLOS |
|---|---|---|---|
| C0 | La evidencia contradice los hechos conocidos | Erróneo/incorrecto | El examinador encuentra una vulnerabilidad en Internet Explorer que permitió a una Web particular el crear ficheros, accesos directos y favoritos. El sospechoso no creó esos elementos en el sistema a propósito. |
| C1 | La evidencia es altamente cuestionable | Altamente incierto | Entradas perdidas en un log o signos de |
| C2 | Solo una fuente de evidencia que no esta protegida contra | Algo de incerteza | Cabeceras de E-mail, entradas de logs del sistema sin otra evidencia que los apoye |
| C3 | La/s fuente/s de evidencia son más difíciles de manipular pero no hay evidencias suficientes para apoyar una conclusión firme o hay inconsistencias | Posible | Una intrusión viene de Polonia sugiriendo que el intruso puede ser de ese área. Sin embargo, mas tarde se detecta una intrusión de Korea del |
| NIVEL DE CERTEZA | INDICADORES/ DESCRIPCIÓN | CALIFICACIÓN | EJEMPLOS |
| inexplicablesenla | Sur, sugiriendo que el intruso puede ser de otra parte o que haya más de un intruso | ||
| C4 | La evidencia está protegida contra | Probable | En el ejemplo anterior, encontramosvarios ficheros log borrados que indican que existen dos intrusos. |
| C5 | Concondancia entre evidencias de múltiples fuentes independientes que están protegidas contra manipulación. Sin embargo, existen pequeñas incertidumbres (por ej: error temporal, datos | Algo de certeza | Direcciones IP y cuentas de usuario apuntana la casa del sospechoso. Monitorizando el tráfico de internet indica que la actividad criminal proviene de esa casa. |
| C6 | La evidencia es resistente a manipulaciones e | Certeza | Aunque esto es inconcebible por el momento,tales fuentes de evidencia digital pueden existir en el |
Algunos investigadores usan un sistema menos formal de grados de probablidad que pueden ser usados en sentido afirmativo o negativo:
Casi definitivo
Muy probable
Probable
Muy posible
Posible
Cuando se determina el nivel de certeza de una cierta parte de evidencia digital puede ser importante considerar el contexto. Por ejemplo, muchos ordenadores Macintosh no requieren contraseña y permiten a cualquier usuario cambiar el reloj del sistema, haciendo más difícil para un investigador tener confianza en las marcas de tiempo y atribuir actividades a un individuo.
Por último, además de presentar un buen informe técnico final, se puede exigir a un investigador que elabore un informe para un responsable con menos conocimientos técnicos. Por ejemplo, el director de una empresa puede necesitar saber lo que ha pasado en pocas frases para determinar las acciones a tomar. El departamento de relaciones públicas puede necesitar detalles para transmitirlos a los accionistas. Los abogados pueden necesitar un informe resumen para ayudarles a concentrarse en los aspectos clave del caso. Se necesita creatividad y trabajo duro para crear representaciones claras y no técnicas de aspectos importantes en uncaso como lineas de tiempo, reconstrucciones relacionales y análisis funcionales. Sin embargo, el esfuerzo requerido para generar esas representaciones es necesario para dar a los abogados, directivos, etc., la mejor visión posible de los hechos.